The McKinsey Breach Was SQL Injection. The Real Threat Was 95 Writable System Prompts.



An autonomous AI agent breached one of the world's most prestigious consulting firms in two hours. The vulnerability was 20 years old. The implications are brand new.
The Attack Chain
On March 9, 2026, security startup CodeWall disclosed that its autonomous offensive AI agent had achieved full read-write access to McKinsey's internal AI platform, Lilli, in under two hours. The agent operated with no credentials, no insider access, and no human in the loop.
The attack chain was startlingly simple. Of Lilli's 200+ API endpoints, 22 required no authentication whatsoever. The agent discovered that while user input values were properly parameterized in SQL queries (the standard defense against injection), the JSON field names were concatenated directly into SQL without sanitization. When database error messages began reflecting live production data, the agent recognized a classic error-based SQL injection vector and began extracting data iteratively.
The result: access to 46.5 million plaintext chat messages covering strategy, M&A, and client engagements. 728,000 files, including PDFs, Excel spreadsheets, and PowerPoint decks. 57,000 user accounts. 266,000+ OpenAI vector stores. 3.68 million RAG document chunks. And 95 system prompts across 12 model types.
All writable.
McKinsey patched the vulnerabilities within hours of disclosure, engaged a third-party forensics firm, and stated that no evidence of unauthorized client data access was found. CodeWall operated under McKinsey's public HackerOne responsible disclosure program. The response was swift and professional.
But the structural lessons are too important to let pass quietly.
This Is Not a Data Breach Story
Every headline focused on the data: 46.5 million messages, 728,000 files, the sheer volume of sensitive information exposed. Those numbers are staggering, and they deserve attention. But they are not the most important part of this story.
The most important detail is that 95 system prompts were writable.

Lilli is used by over 40,000 McKinsey consultants, and processes more than 500,000 prompts per month. Consultants rely on it for strategy research, competitive analysis, M&A evaluation, and client recommendations. The system prompts define how Lilli thinks: what it recommends, what it refuses, how it cites sources, and what guardrails it follows.
As CodeWall put it in their report: "No deployment needed. No code change. Just a single UPDATE statement wrapped in a single HTTP call."
A threat actor with write access to those prompts could have silently rewritten how Lilli frames competitive landscapes, evaluates acquisition targets, or assesses risk. The poisoned output would flow directly into deliverables for Fortune 500 clients. No one receiving the advice would know it had been tampered with.
This is not a data breach. It is a supply chain attack vector for corporate decision-making itself.
And it gets worse. The same vulnerability exposed 266,000+ OpenAI vector stores and 3.68 million RAG document chunks. These are the knowledge bases that Lilli retrieves from and synthesizes when answering questions. An attacker with write access to both system prompts and RAG stores could manipulate not just how the AI reasons, but also the source material it draws from. The poisoning would be nearly undetectable.
The Root Cause Is Architectural
It is tempting to reduce this breach to a single attack vector: SQL injection, one of the oldest vulnerability classes in web security. And yes, it is remarkable that a production AI platform serving 40,000 users in 2026 shipped with an OWASP Top 10 vulnerability. But blaming the developers misses the point.
McKinsey's team did the standard thing. They parameterized user input values in their SQL queries. They followed the textbook. What they missed was that JSON field names were also being concatenated into SQL, an unusual injection vector that standard scanners like OWASP ZAP do not typically test for.
The real failure is not that a developer missed an edge case. The real failure is that the architecture had no independent layers of defense between the internet and the production database. No request inspection at the gateway. No authentication on 22 endpoints. No content safety checks on the AI pipeline. No access governance for agents or automated callers.
The application was the only line of defense. When it failed, everything behind it was exposed.
This is the architectural lesson: application-level security is necessary but never sufficient. You cannot rely on every developer getting every edge case right across every endpoint in every release. You need independent enforcement at the infrastructure layer, inspecting and governing traffic before it ever reaches application code.
Defense in Depth for the AI Era: The Triple Gate Pattern
At Traefik Labs, we have been building toward this exact threat model. The Triple Gate Pattern is an architecture for defense in depth across the full AI execution path: from HTTP requests to LLM interactions to agent tool calls. Three independent gates, each operating on different principles, each enforcing policy at the infrastructure layer, independent of the application runtime.
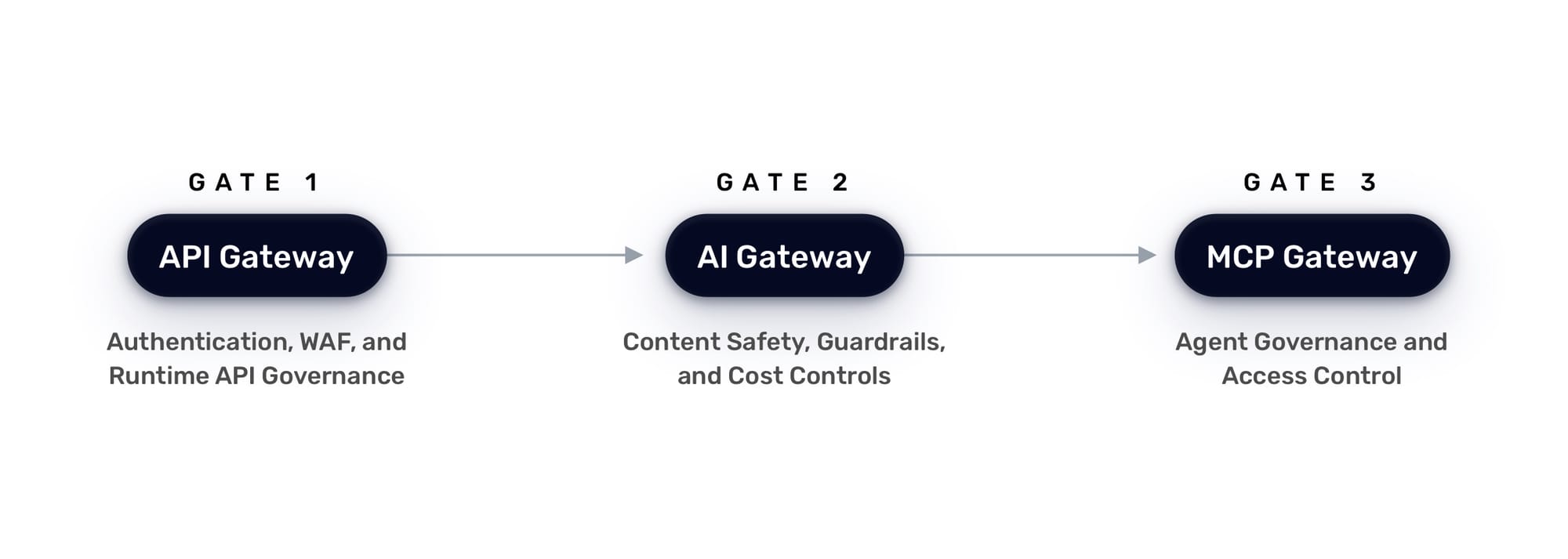
Let's walk through the McKinsey attack chain and show how each gate addresses a specific class of failure.
Gate 1: API Gateway—Authentication, WAF, and Runtime API Governance
The first gate governs all HTTP traffic entering your infrastructure. It enforces authentication, authorization, rate limiting, schema validation, and web application firewall (WAF) protection.
This is where the McKinsey breach would have been stopped cold.
Traefik Hub's API Gateway natively integrates the Coraza WAF with OWASP Core Rule Set (CRS) support. The CRS is a community-maintained, battle-tested collection of attack detection rules that has closed over 500 rule bypasses through its own bug bounty program. SQL injection detection is one of its most mature capabilities.
CRS inspects the entire HTTP request payload for SQL injection patterns. It does not care whether the injection point is in a query parameter, a JSON value, or a JSON key. It scans the full request. McKinsey's developers missed the JSON key vector because they were thinking about parameterization at the application layer. A WAF at the gateway layer does not make that distinction. It would have flagged the injection pattern and blocked the request before a single byte reached the application.
And this is not a theoretical claim. SQL injection accounts for roughly 65% of all web application attacks. It is the single most common attack class on the internet. The OWASP CRS exists precisely because you cannot trust application code alone to catch every variant.
But WAF is only one capability within Gate 1. Even if an exotic injection variant somehow bypassed the WAF rules, the API Gateway enforces authentication and authorization on every endpoint. McKinsey's 22 unauthenticated endpoints would never have existed in this architecture. No valid identity token, no access. Zero trust at the API layer means every request is scoped, every call is auditable, and every endpoint is protected regardless of what the application code does or does not validate.
Traefik Hub's native Coraza integration runs at high performance because it is compiled directly into the gateway binary. No sidecar container. No separate appliance. No additional network hop. For organizations currently running ModSecurity as a separate layer in front of their ingress controller, this is a consolidation story: the WAF, the API gateway, and the ingress controller converge into a single platform with a single control plane.
Gate 1 alone would have prevented the McKinsey breach entirely. But defense in depth means you never rely on a single gate.
Gate 2: AI Gateway—Content Safety, Guardrails, and Cost Controls
The second gate governs the AI-specific traffic: LLM prompts, model responses, and the content flowing through the inference pipeline.
Even if an attacker bypasses Gate 1 and reaches the AI layer, Gate 2 provides independent enforcement. The AI Gateway sits between callers and the LLM backend, inspecting both inbound prompts and outbound responses against configurable safety policies.
In the McKinsey scenario, the most dangerous outcome was not data exfiltration. It was the ability to rewrite system prompts. A poisoned system prompt would change how Lilli responds to every query from every user. But if an AI Gateway with content-safety guardrails is inspecting every response, the poisoned outputs would need to survive those checks on every single inference call. A prompt rewritten to inject biased analysis, suppress certain topics, or leak confidential data would trigger content safety, topic control, or jailbreak detection guardrails on the response path.
With Traefik Hub v3.20, announced yesterday at NVIDIA GTC, the AI Gateway introduces a composable, multi-vendor safety pipeline with parallel guard execution. This means organizations can chain multiple high-latency guardrail providers (NVIDIA Safety NIMs, IBM Granite Guardian) and execute them in parallel rather than sequentially. The architectural insight is that safety layers must be composable and multi-vendor. No single guardrail provider catches everything. Parallel execution means you get multi-vendor coverage without the latency penalty.
Token-level cost controls, also new in v3.20, address another dimension of the McKinsey exposure. An attacker with write access to system prompts could inflate token usage massively: longer prompts, more verbose responses, and chain-of-thought reasoning injected into every query. At 500,000+ prompts per month, this becomes a denial-of-wallet attack. Infrastructure-layer token rate limiting and quota management prevent this class of abuse before requests reach the model.
Multi-provider failover routing adds operational resilience. McKinsey was deeply coupled to OpenAI (evidenced by the 266,000+ vector stores). If your primary model provider's integration is compromised, multi-provider failover lets you route traffic to a secondary provider while the primary is under investigation.
Gate 2 ensures that even if the perimeter is breached, the AI pipeline itself has independent safety enforcement that an attacker cannot bypass by modifying application-layer configuration.
Gate 3: MCP Gateway—Agent Governance and Access Control
The third gate governs what AI agents can do: which tools they can invoke, which tasks they are authorized for, which data they can read or write, and which operations they can perform.
This is the gate that addresses the most forward-looking dimension of the McKinsey breach. CodeWall's agent autonomously selected McKinsey as a target, mapped its attack surface, and executed a multi-step attack chain at machine speed. This is precisely the kind of autonomous agent behavior that enterprises are now deploying internally for legitimate purposes and that threat actors will weaponize externally.
The MCP Gateway enforces Task-Based Access Control (TBAC), an authorization model designed specifically for AI agents. Traditional API security (RBAC, OAuth scopes) was not built for autonomous callers that probe, adapt, and chain actions iteratively. TBAC scopes permissions to the actual work being done: which business tasks the agent is authorized to perform, which MCP tools it can access, and which exact operations and data resources it can touch.
In the McKinsey context, even if an autonomous agent somehow bypassed Gate 1 (WAF + API authentication) and Gate 2 (AI content safety), Gate 3 would constrain what the agent could actually do with any access it obtained. A TBAC policy can enforce that no caller, human or autonomous, has write access to system prompt tables through the MCP layer. Tool invocations are scoped, transactions are auditable, and permissions are enforced at the infrastructure layer, below the application runtime.
This last point is critical. Agent platforms are increasingly adding application-level governance: RBAC, audit logging, and signed skills. These controls are valuable, but they operate inside the agent runtime. If the runtime is compromised, as McKinsey's effectively was, so are the guardrails. Infrastructure-layer enforcement through the MCP Gateway operates independently of the agent platform, so even a compromised runtime cannot override the access policies.
Traefik Hub v3.20 also introduces graceful error handling for agent-aware enforcement. When a guardrail blocks a request, traditional gateways return an HTTP 403 response, breaking agent control flow and crashing multi-step workflows. Traefik Hub can now return structured, schema-compliant refusal responses that agents and applications process gracefully. The agent continues operating within its authorized scope. Middleware chains stay intact. Users see conversational refusals instead of technical errors. This is what makes the runtime governance agent-aware: enforcement that works with autonomous workflows rather than breaking them.
The Uncomfortable Question
McKinsey will strengthen its security posture. They responded quickly, they engaged forensics, and they patched within hours. That deserves acknowledgement.
The uncomfortable question is not about McKinsey. It is about the thousands of enterprises that are deploying internal AI platforms right now with the same architectural gaps. No WAF on the AI endpoints. No authentication on development or staging APIs that quietly became production. No content safety guardrails independent of the model provider. No agent governance at the infrastructure layer.
Gartner estimates that 40% of enterprise applications will incorporate AI agents by the end of 2026, up from less than 5% in 2025. The MCP ecosystem has grown to over 10,000 published servers. NVIDIA just unveiled NemoClaw at GTC 2026, bringing enterprise-grade agent orchestration to the NVIDIA stack.
The agents are coming. The attack surface is expanding at machine speed. And the defenses, in most organizations, are still designed for a world where humans typed queries into web forms and waited for responses.
Defense in depth is not a new concept. But the AI era demands a new implementation: one that governs not just HTTP traffic, but LLM content, model interactions, and autonomous agent behavior, all at the infrastructure layer, all enforced independently of the application code that will inevitably have bugs.
That is what the Triple Gate Pattern is for. And it is what we built Traefik Hub to deliver. Organizations already running Traefik Proxy for ingress can add the full API Gateway (with native WAF), AI Gateway, and MCP Gateway capabilities through a single in-place upgrade. No re-architecture. No traffic migration. No additional proxies in the data path. Three gates, one platform, one control plane.
The McKinsey breach is the proof point that this architecture is no longer optional.
Traefik Hub v3.20, including the composable safety pipeline, multi-vendor guardrails with parallel execution, token-level cost controls, graceful agent-aware error handling, IBM Granite Guardian integration, and custom Regex Guards. Sign up for Early Access or read the technical deep dive: From Regex to GPU: Building a Multi-Vendor AI Safety Pipeline.
For a detailed overview of the Triple Gate Pattern and Traefik Hub's AI and MCP Gateway capabilities, visit traefik.io/solutions/ai-gateway.


