How to Choose the Right Load Balancing Strategy for Your Use Case


In a previous article on advanced load balancing, we explored features like sticky sessions, health checks, and traffic mirroring. Those are the tools. This article covers the strategy.
Your application runs smoothly with round-robin load balancing. Traffic distributes evenly, everything works. Then you notice some requests take 50ms, others 500ms. Monitoring shows all servers are healthy, but user experience is inconsistent. The problem isn't if you're load balancing—it's how.
Load balancing strategies determine which server handles which request, and this decision has a direct impact on performance, cost, and user experience. Choosing the wrong strategy is like taking the highway when you need to navigate city streets—you might eventually get there, but you're not adapting to the terrain.
Traefik's load balancing strategies map to specific technical requirements. Weighted Round Robin (WRR) works for uniform backends. Power of Two Choices (P2C) handles variable connection lifetimes. Highest Random Weight (HRW) optimizes caching. Least-Time adapts to heterogeneous performance.
Understanding the Landscape: Features vs. Strategies
First, an important distinction:
Load balancing features (sticky sessions, health checks, mirroring) define capabilities—what your load balancer can do.
Load balancing strategies define decision-making—which server gets the next request.
In other words, features are your car's options: heated seats, navigation, backup camera. Strategies are your driving style: highway cruising, city maneuvering, off-road driving.
Both matter, but serve different purposes. This article focuses on strategies—the algorithms that route your traffic.
The Four Core Strategies: Overview
Traefik supports four primary load balancing strategies at the server level:
| Strategy | How It Works | Why Choose It |
|---|---|---|
| WRR (Weighted Round Robin) | Fair rotation with optional weights | General-purpose, predictable workloads |
| P2C (Power of Two Choices) | Pick 2 random servers, choose the one with fewer connections | Dynamic scaling, variable connection lifetimes |
| HRW (Highest Random Weight) | Consistent hashing per client | Cache optimization, client affinity |
| Least-Time | Lowest response time + active connections | Heterogeneous backends, performance optimization |
Each strategy maps to specific business scenarios.
Matching Strategy to Your Use Case
These scenarios are presented in order of increasing complexity, but choose based on your technical requirements, not your company size or stage. A caching-heavy product should use HRW from day one, while a large-scale service with uniform workloads might use WRR forever.
Scenario 1: Simple and Predictable—WRR
Great for: Internal tools, stable production services
Use When
- Homogeneous backends (all servers are similar)
- Predictable traffic patterns
- Simplicity and reliability are priorities
- You don't need advanced optimization
The Problem You're Solving
You've deployed three identical application servers and need to distribute traffic. Your focus is on uptime and simplicity—not premature optimization.
The Solution: Weighted Round Robin (WRR)
WRR is Traefik's default strategy. It distributes requests in a predictable, fair rotation:
http:
services:
my-api:
loadBalancer:
servers:
- url: "http://server-1:8080"
- url: "http://server-2:8080"
- url: "http://server-3:8080"With WRR, if you send 300 requests, each server handles approximately 100 over time. Simple, predictable, reliable.
When to Add Weights
When you have servers with different capabilities, WRR's weight system lets you send proportionally more traffic to more powerful machines. The higher the weight, the more traffic the server gets.
http:
services:
my-api:
loadBalancer:
servers:
- url: "http://small-server:8080"
weight: 1
- url: "http://medium-server:8080"
weight: 2
- url: "http://large-server:8080"
weight: 4 # Gets 4x traffic over time of small serverBenefits and Trade-Offs
WRR delivers predictable costs and straightforward capacity planning. Troubleshooting is simple since you always know which server handled a request.
The trade-off: WRR doesn't adapt to real-time conditions. All requests are treated equally, regardless of complexity or current server load.
Consider Other Strategies When
Your infrastructure becomes heterogeneous, connection lifetimes vary significantly, or you need caching/performance optimization.
Scenario 2: Variable Connection Lifetimes—P2C
Great for: Real-time applications, auto-scaling environments
Use When
- Variable connection lifetimes (WebSockets, long-polling, streaming mixed with short requests)
- Auto-scaling infrastructure (servers frequently added/removed)
- Connection count imbalance is causing performance issues
- You need automatic load distribution without manual tuning
The Problem You're Solving
You've implemented auto-scaling, but you notice uneven load distribution. Some servers are overloaded while others are idle. Your monitoring shows:
- Server A: 150 active connections, CPU at 80%
- Server B: 30 active connections, CPU at 20%
- Server C: 200 active connections, CPU at 95%
Your Weighted Round Robin (WRR) strategy keeps sending traffic to Server C even though it's struggling.
The Solution: Power of Two Choices (P2C)
P2C uses a simple algorithm (hence the name): randomly pick two servers, then choose the one with fewer active connections.
http:
services:
my-api:
loadBalancer:
strategy: "p2c"
servers:
- url: "http://server-1:8080"
- url: "http://server-2:8080"
- url: "http://server-3:8080"How It Works
- Request arrives
- Traefik randomly selects two servers (say, A and C)
- Compares their active connection counts
- Routes to the less loaded server (A has 150, C has 200 → choose A)
This simple algorithm balances connections effectively with minimal overhead.
Real-World Scenario: Real-Time Collaboration Platform
You run a SaaS collaboration platform (think Figma, or Google Docs) that combines real-time editing with standard API operations.
Your infrastructure handles:
- Quick API calls: Loading documents, saving comments (50-200ms, connection closes immediately)
- Live editing sessions: WebSocket connections for real-time collaboration (users stay connected for 30-60 minutes while editing)
- File operations: Document exports, image uploads (30-90 second connections)
With WRR, all servers initially get equal requests, but connection lifetimes vary dramatically. Server A has 8 active editing sessions and 8 WebSockets open for the next hour. Server B has 150 quick API calls that all completed, and the server is now idle. Server C has 5 file uploads and the connections are held for 60 seconds.
WRR keeps distributing requests evenly, regardless of active connections. Once a new editing session starts, it's sent to the already-loaded Server A.
Now Server A is overloaded, Server B is underutilized, and users wonder why their editing sessions is so laggy.
With P2C, however, Traefik randomly picks two servers, compares active connection counts. It recognizes that Server A has 8 connections and Server B has 0, so Traefik routes to Server B.
Long-lived editing sessions naturally spread across available capacity, while quick API calls fill gaps on less-loaded servers. The result is smooth real-time collaboration for all users with optimal resource usage.
Benefits and Trade-Offs
P2C automatically distributes load without manual tuning, handling mixed workloads gracefully. It reduces hot spots and improves resource utilization, which translates to lower cloud costs.
The trade-off: P2C only considers connection count, not processing time. A server handling 10 lightweight requests looks the same as one handling 10 heavy requests. The random selection also makes debugging slightly less predictable than WRR.
Consider Other Strategies When
You need client affinity for caching (HRW), or backend performance varies significantly (Least-Time).
Scenario 3: Cache Optimization—Client Affinity with HRW
Great for: Any stage with caching requirements (CDNs, personalization platforms, session-heavy apps)
Use When
- Stateful backends or caching layers
- Users benefit from hitting the same server repeatedly
- Cache hit rate is more important than perfect load distribution
- You have session data, user-specific caches, or personalized content
The Problem You're Solving
You have multiple backend servers, each building up its own cache (Redis, in-memory, CDN edge). With P2C or WRR, a single user's requests bounce between different servers, resulting in:
- Cache misses (user's data isn't on the selected server)
- Repeated cache warming for the same user across servers
- Wasted memory and processing power
The Solution: Highest Random Weight (HRW)
HRW (also called Rendezvous hashing) uses consistent hashing to map clients to servers deterministically.
http:
services:
cached-api:
loadBalancer:
strategy: "hrw"
servers:
- url: "http://cache-server-1:8080"
- url: "http://cache-server-2:8080"
- url: "http://cache-server-3:8080"How it works:
- Traefik hashes the client's IP address
- Calculates a score for each server using the hash
- Consistently routes that client to the highest-scoring server
- Same client routes to same server unless servers are added/removed
- When servers change, only ~1/N clients get remapped (vs. 100% with simple hash % server_count)
Real-World Scenario: User-Specific Content Caching
You run a personalized recommendation platform. Each server builds in-memory caches of user preferences, browsing history, and ML model outputs.
With WRR/P2C, a user requests a recommendation, which is routed to Server A→ cache miss → compute (100ms). The same user makes a second request, which is then routed to Server B → cache miss → compute (100ms). The result is frequent cache misses (users randomly distributed across servers) and high CPU usage across all servers.
With HRW, a user requests a recommendation, which is routed to Server A (based on client hash) → cache miss → compute and cache (100ms). The user's second request, however, is also routed to Server A (same hash) → cache hit (5ms). With HRW, cache hit rates climb since users consistently hit the same server, which significantly reduces CPU usage from cache efficiency.
Benefits and Trade-offs
HRW maximizes cache efficiency by ensuring the same client consistently hits the same server. This reduces origin load and makes debugging straightforward since routing is deterministic.
The trade-off is that HRW prioritizes consistency over load distribution. If one client generates disproportionate traffic, its assigned server becomes a hotspot. Adding or removing servers also requires careful planning since it triggers client remapping.
Consider Other Strategies When
Load imbalance becomes problematic, or backend performance varies significantly and you need adaptive routing (Least-Time).
Scenario 4: Performance Optimization—Adaptive Routing with Least-Time
Great for: High-traffic applications, performance-critical services, and heterogeneous infrastructure
Use When
- Backend performance varies (mixed instance types, different hardware)
- Every millisecond of latency matters
- You want automatic adaptation to performance changes
- Backends have different processing speeds
The Problem You're Solving
Your infrastructure uses mixed instance types:
- Server A: High-performance dedicated server (5ms average response)
- Server B: Standard cloud instance (15ms average response)
- Server C: Cheaper instance with variable performance (10-50ms)
With previous strategies, you face impossible trade-offs:
- WRR: Treats all servers equally, users randomly get slow responses
- P2C: Balances connections but ignores that Server A is 3x faster
- HRW: Sticks users to potentially slow servers
The Solution: Least-Time Strategy
Least-Time combines response time measurement with active connection tracking to route intelligently
http:
services:
backend:
loadBalancer:
strategy: "leasttime"
servers:
- url: "http://fast-server:8080"
- url: "http://standard-server:8080"
- url: "http://variable-server:8080"How It Works
For each server, Traefik calculates a score based on recent response times (Time To First Byte) and active connections. Requests are routed to the server with the lowest score. Fast servers with few active connections automatically get more traffic, while degrading servers are deprioritized.
Real-World Scenario: Mixed Instance Types with Weighted Least-Time
Your application runs on heterogeneous infrastructure:
- Server A: High-performance dedicated instance (5ms average API response)
- Server B: Standard cloud instance (15ms average API response)
- Server C: Burstable instance with variable performance (10-50ms depending on CPU credits)
With WRR, all servers receive equal traffic. Users randomly experience 5ms, 15ms, or 50ms responses, which creates an inconsistent user experience. Fast Server A is underutilized while slow Server C gets equal load.
With Least-Time, however, Traefik measures each backend's actual response time (TTFB). Server A (fastest) automatically receives more traffic, while Server C receives less traffic when its CPU credits are depleted. Then, when Server C performance improves, traffic naturally increases. The user experience is consistent, and resource utilization is optimal.
Using weights for capacity-aware routing:
http:
services:
backend:
loadBalancer:
strategy: "leasttime"
servers:
- url: "http://high-perf-server:8080"
weight: 3 # Premium instance, can handle more
- url: "http://standard-server-1:8080"
weight: 1
- url: "http://burstable-server:8080"
weight: 1Weights indicate capacity. A server with weight=3 can handle 3x the traffic before its score becomes unfavorable, allowing you to maximize value from premium infrastructure.
Benefits and Trade-Offs
Least-Time delivers near-optimal performance by routing to the fastest available backend. It adapts automatically when servers degrade—no manual intervention required. This leads to better resource utilization and graceful degradation without hard failovers. It's particularly effective for mixed infrastructure where backend performance varies.
The trade-off is: accurate routing depends on stable network conditions for reliable measurements. There's also slight computational overhead from tracking response times, though this is negligible in practice.
Beyond Server Strategies: Service-Level Load Balancing
So far, we've discussed server-level strategies—how to distribute traffic among backend instances. Traefik also offers service-level strategies for advanced patterns:
Weighted Round Robin (Service Level)
Distribute traffic between different services (not just servers). This is perfect for:
- Canary deployments: 95% to stable version, 5% to new version
- Blue-green deployments: Gradual traffic shifting
- A/B testing: Route percentage of users to experiment variants
http:
services:
app:
weighted:
services:
- name: stable-v1
weight: 95
- name: canary-v2
weight: 5Mirroring
Duplicate traffic to multiple services, which is essential for:
- Testing new versions with real traffic (without risking production)
- Performance comparisons between implementations
- Data pipeline validation
http:
services:
api-with-mirror:
mirroring:
service: production-api
mirrors:
- name: new-api-version
percent: 10 # Mirror 10% of trafficFailover
Automatic fallback when primary service fails:
http:
services:
resilient-api:
failover:
service: primary-cluster
fallback: backup-clusterCombining Server and Service-Level Strategies
You can combine strategies at multiple levels. For example, you can use Least-Time at the server level for each service, and weighted service-level balancing for canary deployments:
http:
services:
# Service-level: Weighted between versions
app:
weighted:
services:
- name: v1-backend
weight: 90
- name: v2-backend
weight: 10
# Server-level: Least-Time within each version
v1-backend:
loadBalancer:
strategy: "leasttime"
servers:
- url: "http://v1-server-1:8080"
- url: "http://v1-server-2:8080"
v2-backend:
loadBalancer:
strategy: "leasttime"
servers:
- url: "http://v2-server-1:8080"
- url: "http://v2-server-2:8080"Conclusion: Choosing Your Strategy
Use this decision tree to select the best strategy for your use case:
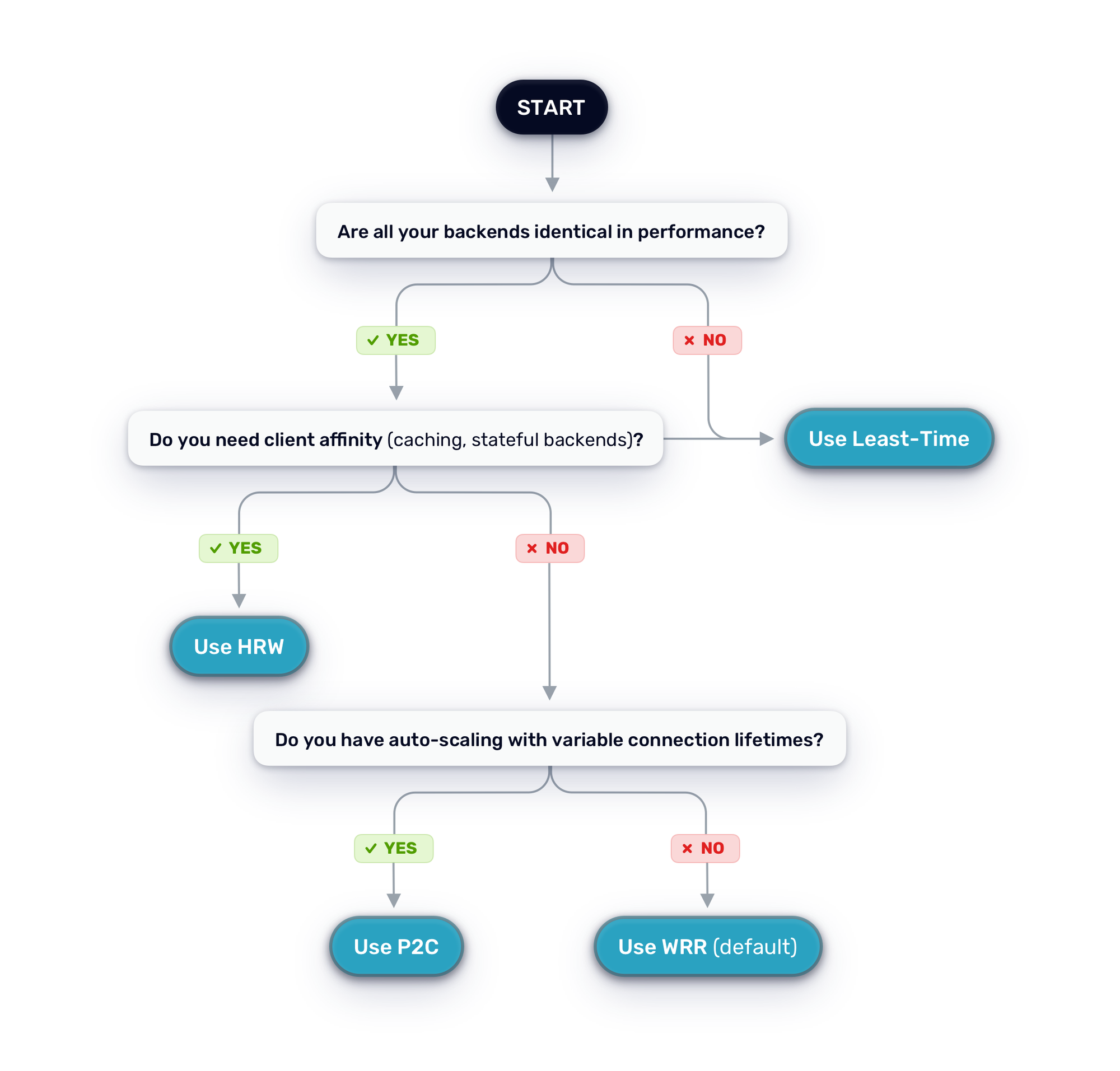
Quick Reference Table
| Your Scenario | Recommended Strategy | Why It's Best |
|---|---|---|
| Identical servers, uniform requests | WRR | Simple, predictable, no overhead |
| Auto-scaling, variable connection lifetimes | P2C | Balances connection count dynamically |
| Client affinity for caching, stateful backends | HRW | Consistent client→server mapping |
| Different server types/performance | WRR with weights | Proportional to capacity |
| Heterogeneous backends, latency-sensitive | Least-Time | Optimizes for actual performance |
| Canary/blue-green deployments | Weighted (service-level) | Control traffic percentage |
| Testing with production traffic | Mirroring | Safe real-world validation |
Load balancing isn't one-size-fits-all—but it doesn't have to be complicated either. Start with WRR, measure your system's behavior, and evolve deliberately.
Traefik lets you change strategies without downtime, so you can adapt as your requirements change.
Further Reading
- Traefik Load Balancing Documentation
- Our previous article on advanced load balancing features
- Traefik Community Forum for real-world advice and support
Have questions or success stories? Share them in the comments below or join the conversation in our community forum.


