Harness Engineering vs Platform Engineering: A Mental Model for How Both Win



Two posts in early 2026 reframed how the industry thinks about agent quality. LangChain's Deep Agents team published harness engineering numbers that moved their coding agent from outside the Top 30 to rank 5 on Terminal-Bench 2.0, a 13.7-point gain achieved by holding GPT-5.2-Codex fixed and changing only system prompts, tools, and middleware. A few weeks later, Cursor published a long read on how its harness team manages context, classifies errors, runs continuous A/B tests, and tunes per model family. Then came the Cursor SDK, exposing the harness as a programmable surface to anyone. Anthropic's Opus 4.7 release notes called out self-verification as a built-in model capability. A new vernacular took hold: the model is one half, the harness is the other, and anything not in the model lives in the harness.
The conclusion most readers drew was that the harness is the product. That is a useful corrective. It pushes back on the model-of-the-month obsession and puts attention on the engineering work that actually compounds.
But the harness is only half the architecture. The other half is platform engineering, and the boundary between the two is the most consequential decision an enterprise architect makes when planning agentic systems at scale.
An earlier post argued that AI cross-cutting concerns belong at the platform layer for the same reasons HTTP cross-cutting concerns ended up at the API gateway over the past decade. This post takes that conclusion as given and asks the next question: where exactly is the line between platform and harness, what does each plane own, and why does the line keep getting blurred in the field?
What Harness Engineering Actually Owns
A harness is everything wrapping the model inside a single agent process. Anatomies vary, but a useful decomposition has emerged across the major harness publications:
The orchestration loop (the ReAct or Thought-Action-Observation cycle), system prompt assembly, tool definitions and tool-call execution, hooks and middleware around model and tool calls, sub-agent delegation, in-process memory and state, sandboxed code execution, context window compression and offloading, lifecycle management for sessions, structured output parsing, and self-verification logic.
Every one of these decisions is task-specific or model-specific. The harness is where domain knowledge about a particular agent's job lives. It is the right place to encode that a coding agent should re-read its own diff before declaring done, that a research agent should plan then execute, that a support agent should escalate after three failed tool calls. The harness optimizes for one agent's task performance, token budget, and latency profile.
Three things follow from this scope. First, harness engineering is fundamentally an application-layer discipline. Second, harness improvements compound through observation, with techniques like tracing, evaluation harnesses, and iterative tuning against benchmarks. Third, every harness optimizes for itself.
What Platform Engineering Owns
Production agents do not run alone. A single enterprise will run dozens, often hundreds. Different teams pick different harness frameworks. Some agents call frontier APIs, some call self-hosted models, some call sovereign deployments. Some agents call MCP servers operated by the same company; others call MCP servers run by partners or third parties. Some agents serve internal users; others serve external customers under different commercial and regulatory terms.
The concerns that span this fleet are platform engineering concerns. Identity and authentication of the calling agent. Authorization of which tools and data each agent can touch. Audit records that a regulator or incident responder can read. Rate limiting and concurrency control across tenants. Cost attribution and FinOps quotas. Secrets handling. Content filtering for prompt and response payloads. Regional routing for data residency. Failover and circuit breaking when a model provider degrades. Consistent observability across the full traffic graph.
These concerns share three properties. They must be enforced consistently across agents built by different teams using different frameworks. They must be auditable from a single control point. And they must outlive any individual harness or model choice, because the harness ecosystem is moving faster than any enterprise can refactor.
The Triple Gate Pattern (API Gateway for north-south application traffic, AI Gateway for model traffic, MCP Gateway for tool and data-source traffic) is one expression of this platform layer. The specific pattern matters less than the architectural principle: every call leaving the agent process traverses a governed control point.
The Reference Architecture Blueprint
A complete agentic system has three layers with clear seams between them.
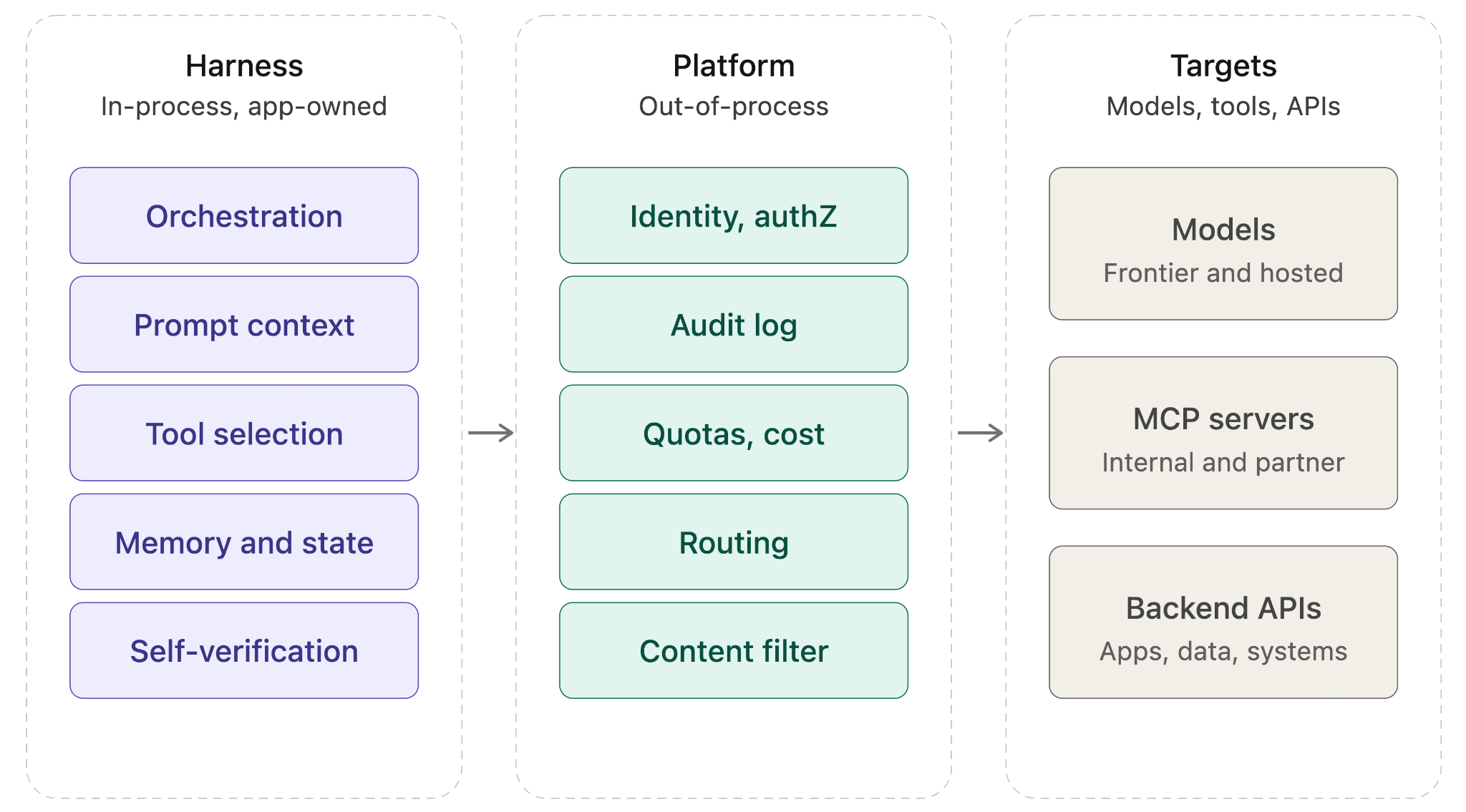
Layer 1: The harness, in-process. Owns orchestration, prompt assembly, tool selection logic, sub-agent fan-out, context compression, in-process memory, and self-verification. Owned by the application team. Optimized per agent.
Layer 2: The platform, out-of-process. Owns identity, authorization, audit, rate limits, cost controls, secrets, content filtering, regional routing, failover, and traffic-graph observability. Owned by platform or infrastructure engineering. Enforced uniformly across all agents.
Layer 3: The targets. Models (frontier APIs, self-hosted endpoints, sovereign deployments), tools and MCP servers (internal, partner, third-party), and existing application APIs. Owned by various teams or providers, treated as governed dependencies.
The seam between Layer 1 and Layer 2 is the most important design decision. It is the point at which every model call, every tool invocation, every MCP request leaves the agent process. If that seam is well defined, the harness can evolve independently of the platform. The application team can rip out one harness framework and adopt another without renegotiating governance. The platform team can introduce a new policy without coordinating with every application team.
If the seam is poorly defined, the two layers smear into each other. Authorization decisions end up in harness middleware where the security team cannot audit them. Cost controls end up in platform code where application teams cannot tune them. Every change becomes a cross-team negotiation.
Cross-Cutting Concerns, Mapped
The contested zone is the set of concerns that could plausibly live in either layer. Each entry below passes the cross-cutting test from the previous post (uniformity across applications, no domain knowledge required, systemic blast radius when wrong) but the question this post addresses is sharper: when the call leaves the agent process, what stays inside the harness and what moves to the platform?
Concerns Owned by the Harness (In-Process, Task-Specific)
| Concern | Reasoning |
|---|---|
| Tool selection for a given task | Task-specific; depends on prompt and intermediate state |
| Per-task model selection (capability fit) | Depends on sub-task semantics |
| Sub-agent delegation logic | Internal to one agent's planning |
| Context window compression | Intra-loop performance optimization |
| Self-verification of model output | Task correctness within a single agent |
| Eval and tracing of agent reasoning | Reasoning is internal; benefits from harness-native observability |
| Session persistence and checkpointing | Internal to agent lifecycle |
Concerns Owned by the Platform (Out-of-Process, Fleet-Wide)
| Concern | Reasoning |
|---|---|
| Identity of the calling agent | Must be consistent across harnesses; required for audit |
| Authorization to invoke a tool | Enforces TBAC across all agents; cannot be self-asserted |
| Secrets injection into tool calls | Secrets must not enter the harness process memory |
| Rate limits and concurrency caps | Multi-tenant fairness and provider quotas |
| Per-policy model routing (cost, region, compliance) | Enterprise-wide policy, not per-task |
| Failover when a model provider degrades | Must be transparent to the harness; consistent SLOs |
| Content filtering and DLP on prompts and responses | Regulatory and data-protection consistency |
| Audit trail of every model and tool call | Single source of truth for compliance |
| Traffic-graph observability and correlation | Cross-agent and cross-tenant visibility |
| Cost attribution by team or product | Requires enforcement at the call site, not self-report |
A simple test for any concern not listed: if the answer must be consistent across multiple agent applications, or if a regulator might ask to see it, the concern belongs at the platform. If the answer is task-specific or model-specific within one agent, the concern belongs in the harness.
The Governance Gravitational Pull
Harness frameworks have a recurring pattern of absorbing concerns that belong at the platform layer. Recent harness releases have introduced declarative permission rules in the harness, model routing logic in harness profiles, secrets handled inside the harness process, and audit hooks bolted onto harness middleware. Each of these is technically possible. None of them scale across an enterprise.
The pull is structural, not malicious. Three forces drive it.
The first is commercial. Harness frameworks compete by being indispensable. The more concerns a harness owns, the more switching cost it accumulates. A harness that handles auth, routing, and audit is stickier than one that does only orchestration. From the vendor's perspective, this is rational behavior.
The second is technical. In-process is faster than out-of-process. A permission check that runs locally is microseconds; a check that traverses a network gateway is milliseconds. For a harness optimizing per-task latency, the in-process answer is always tempting.
The third is organizational. Application teams move faster than platform teams. When a coding agent needs a new tool yesterday, asking the platform team to onboard it next sprint is not a workable answer. So application teams build governance shortcuts inside the harness, intending to migrate them later. They rarely do.
The trap closes when the enterprise has five harnesses, each with its own auth model, each with its own audit format, each with its own rate-limit configuration. The CISO discovers there is no single place to ask which agents are allowed to read which data. The FinOps team discovers that cost attribution is inferred from logs scraped after the fact. The compliance team discovers that audit records are scattered across vendor-specific trace stores. By that point, retrofitting platform-layer governance requires touching every harness.
Anti-Patterns
A short list of anti-patterns observed in real deployments.
Auth in the Harness
Authorization decisions are encoded in harness middleware or skill definitions.
Symptom: The security team cannot answer "which agents can call this MCP server" without reading source code from multiple application repositories.
Remedy: Move authorization to a gateway that enforces a uniform policy language, keyed on agent identity and task context.
Per-Product Harness with No Platform
Each product team picks its own harness, runs its own model contracts, and ships independently.
Symptom: Many model contracts, several audit formats, no consolidated cost view.
Remedy: Standardize the platform layer (gateways, identity, audit) before standardizing the harness layer. The platform should be harness-agnostic; the harness should be platform-aware.
Harness Vendor as Governance Vendor
Teams treat a harness framework's enterprise edition as the governance solution.
Symptom: Governance scope is limited to whatever the harness vendor implements; introducing a second harness requires re-implementing controls.
Remedy: Keep governance in the platform layer where it is harness-independent.
Model List in Harness Configuration
Each harness ships with a hard-coded list of supported models and routing rules.
Symptom: Introducing a new model means coordinating updates across every harness; deprecating one is harder still.
Remedy: Harnesses should request a model class (planning, coding, summarization); the AI Gateway resolves the class to a specific model based on policy, region, and cost.
MCP Servers as Direct Dependencies
Harnesses connect directly to MCP servers over the network without an intermediate gateway.
Symptom: Every MCP server reinvents auth, rate limiting, and audit, often badly. The OWASP MCP Top 10 documents the resulting attack surface in detail.
Remedy: MCP traffic flows through an MCP Gateway that handles identity, TBAC, secrets, and audit on behalf of every server behind it.
A Look Forward
Two trends bear watching.
The harness gets thinner over time. Self-verification, planning, and tool use are migrating into the model itself. Opus 4.7's release notes call out attention to instructions and self-verification as model capabilities, which means harness components built specifically to compensate for those gaps will be absorbed. LangChain has acknowledged this trajectory explicitly, framing harness components as bets on what the model cannot yet do.
The platform gets thicker over time. Every regulatory regime that touches AI (the EU AI Act, sector-specific frameworks for finance and healthcare, sovereign data rules) lands at the platform layer because that is where enforcement is possible. Every cost-control reflex inside a CFO organization lands at the platform layer because that is where attribution can be enforced rather than reported. Every breach analysis lands at the platform layer because that is where the audit record lives.
The architectural takeaway is straightforward. Bet that the harness will keep changing. Bet that the platform will keep accreting requirements. Build the seam between them deliberately, and resist the pull to collapse them into one layer.
The harness is not the product. The model is not the product. The platform is not the product. The product is the agent that ships safely, scales economically, and survives an audit. That requires that both the harness and the platform are owned by the right teams and separated by a clean seam.
Frequently Asked Questions
Our harness framework already has an auth plugin. Why isn't that good enough?
It works for one agent. The problem surfaces when the second and third agents ship, built by different teams on different frameworks, each with its own auth plugin configured differently. At that point there is no single place to answer which agents are allowed to call this data source; the answer is scattered across application repositories. Authorization needs to be enforced at a control point that is independent of any individual harness, keyed on agent identity, not on which framework happened to ship a plugin first.
What is the minimum viable platform layer for a team just starting with agents?
Three things: identity for the calling agent, an audit trail of every model and tool call, and a single egress point for model traffic. Everything else (e.g., cost attribution, content filtering, regional routing) can be layered on top. The mistake most teams make is skipping the egress point entirely and wiring agents directly to model APIs. That decision is cheap to make and expensive to undo once the fleet grows.
How do we handle the latency penalty of out-of-process governance?
The penalty is real but routinely overstated. A well-deployed gateway adds single-digit milliseconds to a call that already takes hundreds of milliseconds to complete a model round-trip. The more important question is where latency actually matters in an agentic workflow. And the answer is almost always inside the orchestration loop, which is harness territory. Platform-layer governance sits outside that loop. Optimize the harness for latency; build the platform for correctness and auditability.
We already have three different harness frameworks in production. Where do we start?
Start with the platform, not the harnesses. Standardizing harness frameworks is a multi-team, multi-quarter negotiation. Standardizing the egress layer is not; it is an infrastructure decision that can be made once and applied uniformly. Get identity, audit, and model routing consistent across all three harnesses first. Once the platform seam is clean, harness consolidation becomes optional rather than urgent.
As models absorb more harness capabilities, does the platform layer shrink too?
The opposite. As self-verification, planning, and tool use migrate into the model, the harness gets thinner and the calls leaving the agent process get more consequential, not less. A model that autonomously selects and invokes tools is making more decisions that require audit, authorization, and cost attribution, not fewer. Every capability that moves from the harness into the model is a capability that now needs to be governed at the platform layer rather than observed inside a single agent process.


