Cross-Cutting Concerns Are Back, and the AI Stack Is Abusing the Gateway Pattern


Some architectural problems do not stay solved. They come back every time the system grows by an order of magnitude, with the same root conditions in a more demanding form. Cross-cutting concerns are one such problem.
They were named decades ago, in the era of aspect-oriented programming. They were resolved at the network layer over the 2010s, when API gateways absorbed authentication, rate limiting, observability, and policy enforcement from every microservice and moved them into a shared infrastructure layer. That lesson took roughly a decade to settle, and the cost of learning it was paid in production breaches, audit findings, and engineering rework done late.
The same pattern is now playing out at the AI layer, on a faster timeline, with larger blast radii. The cross-cutting concerns specific to AI traffic, including prompt safety, content filtering, model fallback, agent authorization, token cost governance, and tool poisoning defense, are being implemented in application code, imported Python libraries, and inside individual MCP servers. The deployment data is already mainstream. The case studies are already public. The architectural answer is not new, but the conditions that make it the right answer are stronger in 2026 than at any prior moment.

What Counts as a Cross-Cutting Concern, and What Does Not
A cross-cutting concern is behavior that needs to apply consistently across many parts of a system but does not belong to any one of them. Authentication is the textbook example. Every protected endpoint needs it. None of them defines it. Logging, observability, rate limiting, retries, audit, content safety, encryption in transit, and policy enforcement work the same way. They appear everywhere, but they do not encode the business knowledge of any specific application.
Domain logic is the opposite. The rule that a Premium customer can keep more saved searches than a Standard customer is domain logic. It depends on knowledge of what the application does. It cannot be implemented uniformly across the company because it is specific to this product. It belongs in the application that owns the product.
The line is not always obvious, and that is exactly where things end up in the wrong place. A three-question test sharpens the call.
The uniformity test: would the organization expect every team to implement this exactly the same way? Authentication, yes. Refund eligibility, no.
The domain knowledge test: does the implementation require knowing what the application does? Rate limiting, no. Approving a wire transfer, yes.
The blast radius test: when this behavior is wrong, is the failure systemic or local? An auth bypass shipping in fifty applications is a company-wide incident. A pricing bug in one product is a local incident.
When a behavior is uniform, requires no domain knowledge, and fails systemically when wrong, it is cross-cutting and belongs at a layer that enforces it once for everyone. When it goes the other way, it is domain logic and belongs in the application.
OWASP's API Security Top 10 cleanly illustrates the line. Function-level authorization, the check that asks whether this user is allowed to call this kind of endpoint at all, is cross-cutting. The same logic applies across every endpoint that requires the same role. Object-level authorization, the check that asks whether this user owns this specific record, is closer to domain logic. It depends on the business relationship between the caller and the object. OWASP's guidance is explicit that object-level authorization checks must live in the function that handles the object, because that is where the domain knowledge lives. The rule is not "everything goes in the gateway." It is "each cross-cutting concern goes at the right shared layer, and each domain check stays in the application that knows the domain."
The easiest way to think about this principle is cross-cutting concerns become dangerous when they are implemented locally but expected to behave globally. The risk to watch for is treating a cross-cutting concern as application code and depending on every team across the organization to implement it correctly, consistently, and in lockstep over time.
Why This Matters More in 2026 Than Ever
Six conditions, each more pronounced now than at any prior moment, push cross-cutting concerns out of application code and into a dedicated layer.
1. Scale
A typical enterprise deployment in 2026 runs hundreds to thousands of services, not dozens. Wiz Research's State of AI in the Cloud 2026 report found that 90 percent of analyzed cloud environments run self-hosted AI software on top of an existing microservices estate, with managed AI services in 81 percent and Model Context Protocol servers in roughly 80 percent. Each additional service is another place where authentication, rate limiting, observability, and policy enforcement could drift. The probability that fifty independently implemented copies of an authorization check are all correct at any given moment approaches zero. At a thousand copies, it is zero. Modern scale makes scattered cross-cutting code a statistical certainty of inconsistency.
2. Velocity
Continuous deployment pipelines push code to production multiple times a day, and AI traffic compounds the pressure with model swaps, prompt updates, and tool catalog changes happening on an even faster cadence. When cross-cutting policy lives inside the application, every deployment is a chance to silently disable it. A teammate refactors the auth middleware. A pull request "simplifies" the logging path. A library update changes the default rate-limit behavior. None of these are reliably caught at code review, because the team owns its own policy. They are caught, if at all, by an audit weeks later. A policy enforced at a separate layer, with its own change-management surface and its own deployment cadence, does not drift by accident.
3. Compliance Density
Regulatory frameworks now stack on top of each other in ways they did not in 2015. SOC 2 Type II, ISO 27001, HIPAA, PCI DSS, GDPR, the EU AI Act, the EU Cyber Resilience Act, and sector-specific regulations all require uniform enforcement of access control, data handling, and audit trails. Demonstrating compliance is straightforward when policy is expressed once and enforced uniformly. It is nearly impossible when policy is reimplemented in every application in every language by every team. Auditors do not accept "the policy is in the code" when there are 200 copies of the code.
4. Threat Economics
Attackers automate. The economics of exploitation in 2026 reward adversaries who can detect inconsistencies at machine speed. When one application enforces a rate limit, and another does not, automated reconnaissance finds the gap in minutes. When one MCP server validates tool inputs and another does not, the inconsistency is the attack surface. The IBM X-Force 2026 Threat Intelligence Index reports a 44 percent year-over-year increase in attacks that began with the exploitation of public-facing applications, citing missing authentication controls and AI-enabled vulnerability discovery as primary drivers. Wiz Research has separately observed malware that uses LLMs to dynamically generate commands and adapt execution at runtime. Defenders cannot afford the inconsistency that scattered cross-cutting code produces, because attackers will find it before the audit does.
5. Supply Chain Reality
Modern application code imports tens of thousands of dependencies transitively. Every imported library that handles a cross-cutting concern is a credential and privilege boundary that an attacker can pursue. The LiteLLM compromise in March 2026 made this concrete. When an LLM proxy lives as a Python library inside the application process, compromise of the library is compromise of every credential the application holds. Externalizing the logic to a separate, hardened service that the platform team operates contains the blast radius by design. It is the difference between one credential leak and forty thousand.
6. Polyglot Reality
The modern enterprise stack is not one language. A typical AI-adjacent deployment includes Python application code calling Go inference servers, Rust ingest pipelines, Node.js front ends, and Java backend services. Cross-cutting concerns implemented as Python decorators do not protect the Go service. Rate limiting implemented in a Java filter does not apply to the Rust pipeline. The only way to enforce consistent policy across a polyglot estate is to enforce it at the network boundary that all the languages share.
A seventh condition belongs alongside the sixth, and it is unique to this decade. Token-level cost governance, model fallback and failover, semantic caching, prompt safety, jailbreak detection, PII redaction, and tool-use authorization are cross-cutting concerns that did not exist a few years ago. They cut across applications the same way authentication does, but they also cut across model providers, agent runtimes, and tool catalogs. Centralizing them is not a generalization of an old principle. It is the only practical way to handle them.
These conditions are stronger now than ever. Each one independently argues for moving cross-cutting concerns out of the application runtime. Together, the case is overwhelming.
The API Gateway: A Pattern That Already Worked
The principle has already been proven for HTTP traffic. The API gateway pattern, formalized in the microservices canon and now standard in enterprise architecture, exists because the industry confronted these forces a decade ago at the network layer and concluded that authentication, rate limiting, request validation, observability, and policy enforcement belonged in a single layer rather than scattered across hundreds of services. Microsoft's API gateway guidance states the case directly: the gateway centralizes client-service interaction and performs cross-cutting tasks such as authentication, SSL termination, mutual TLS, and rate limiting. Microsoft's Gateway Offloading pattern, the related architectural reference, identifies certificate management, authentication, SSL termination, monitoring, protocol translation, and throttling as concerns that should be moved out of individual services and into the gateway tier.
The validation came from production telemetry, not from theory. Organizations that placed cross-cutting concerns at the gateway layer ran more reliably, audited more cleanly, recovered from incidents faster, and onboarded new services without re-implementing security primitives. Organizations that did not, paid the cost in breaches, audit findings, and engineering rework. After a decade of empirical settlement, the API gateway became default infrastructure: a tool that platform teams reach for early in any architecture conversation.
That conclusion still holds even though the traffic shape has changed. If anything, the traffic pattern has changed in ways that strengthen the case.
A New Dimension: The Caller May Be an Agent
The original API gateway pattern made an implicit assumption about the caller. The caller was a known type: a human user, a front-end application, an internal service, or a partner integration. Each of those has a stable identity, a request shape that maps cleanly to a documented API, and behavior that does not surprise the operator.
The AI stack changes the caller. An agent, executing a multi-step plan against a model and a tool catalog, may now be the entity deciding which API to call, which MCP tool to invoke, and which prompt to send to which model. The caller is not just sending a request. The caller is interpreting intent, selecting actions, and chaining tool invocations on the fly.
That changes what the cross-cutting concern surface needs to cover.
The controls that gate API access (rate limit, auth, schema validation) are no longer sufficient on their own, because the caller may invoke a sequence of perfectly authorized API calls that, taken together, exfiltrate data the user never had permission to expose, or take actions the user never explicitly approved. OWASP's LLM Top 10 names this risk explicitly as excessive agency: an agent with broad tool access can compose actions in ways no individual permission grant intended. Unbounded consumption is the same risk pointed at cost rather than data.
The caller's inputs are also different. Prompts, retrieved documents, tool descriptions, and tool results are content, not structured requests. Prompt injection therefore becomes a class of vulnerability that a traditional API gateway is not built to detect. OWASP's LLM Top 10 ranks prompt injection as the leading risk to LLM-integrated systems. The MCP specification's own security guidance warns about confused deputy risks, broad tokens, expanded blast radius, audit noise, and privilege chaining as protocol-level concerns that the implementer has to address.
The right response is not to abandon the API gateway. It is to extend the same principle to two new boundaries the AI stack has introduced: the conversation boundary, where prompts and completions live, and the tool-and-action boundary, where agents discover and invoke tools. Each new boundary is its own enforcement point. All three need to operate from the same identity, the same audit trail, and the same policy fabric.
Guardrails Are Not Governance
A useful distinction is becoming clearer in the academic and industry literature on agentic AI risk: prompt-level guardrails, model safety filters, and LLM-as-judge checks are useful signals, but they are not governance. They sit inside the model's probabilistic reasoning loop and depend on the model’s decision to comply with them. That is a layer of defense. It is not enforcement.
A recent paper by Szpruch, Sudjianto, Bhatti, and Ang on scalable runtime governance for agentic AI in financial services, drawing on Model Risk Management practice, makes the architectural case directly. Outcomes in agentic systems emerge from execution trajectories, rather than from a stable input-output mapping. The failures that matter (unsafe tool use, skipped approvals, privacy breaches, uncontrolled side effects) are process failures that surface during runtime, across the sequence of model calls, retrievals, tool invocations, and state transitions that make up the agent's actual work. Effective oversight requires runtime enforcement: governance-semantic telemetry, continuous authorization, temporal policy conformance checking, drift monitoring over trajectory health, and tier-based containment. Related work, including the MI9 framework from researchers at Barclays' Model Risk Management group and the "Policies on Paths" formulation in recent EU AI Act compliance research, converges on the same architectural conclusion.
The implication is direct. Governance for agentic AI cannot live inside the application's own prompt template, inside an in-process guardrail library, or inside the model's instruction tuning. It needs to live at the runtime boundary, where actions, tool calls, identity, approvals, and side effects pass through enforcement points that are independent of the model's probabilistic reasoning.
This is the cross-cutting concern argument restated in the language of regulated AI risk. The runtime governance that the literature is calling for needs a runtime enforcement point. If policy, telemetry, authorization, and containment are embedded separately inside every AI application, every MCP server, and every backend API, the organization has governance in theory but fragmentation in practice.
The AI Stack Is Re-Running the Anti-Pattern
Current AI infrastructure deployment patterns systematically violate the principle the API gateway pattern proved out.
LLM proxy libraries are imported into the application code. LiteLLM, the most widely deployed example, is typically loaded as a Python module running in the application process, holding API keys and routing requests across providers. The proxy lives in the runtime. Every application that wants centralized routing imports its own copy. Every application that imports it inherits the proxy's full security surface, including all the credentials it holds.
Guardrail libraries are imported into the application code. NVIDIA's NeMo Guardrails ships as a Python package that wraps a LangChain chain or any Runnable. The library does what it claims. The architectural placement, however, means that prompt safety lives within whichever team's application imports it. When five applications in the same enterprise each import their own guardrail library with their own configuration, the organization's policy footprint is five distinct rule sets drifting in five different directions.
MCP servers ship with ad-hoc per-server authentication. The Model Context Protocol, introduced by Anthropic in November 2024, has seen extraordinary adoption with over 5,000 community-developed servers within months of release. The current specification references OAuth 2.1, protected resource metadata, and authorization server discovery, but the protocol delegates the actual enforcement to each implementer. MCP standardizes how tools are discovered and invoked. It does not, on its own, standardize how they are governed. When every MCP server is responsible for its own auth, the result is dozens of different auth implementations across dozens of MCP servers, plus a tool-poisoning attack surface where a malicious tool description can hijack the model that is reading it.
Run the three-question test against any of these patterns. Is prompt safety expected to behave uniformly across applications? Yes. Does prompt safety require domain knowledge of each application's functionality? No, with rare exceptions. Is a prompt safety failure systemic when it ships in dozens of apps? Yes. Prompt safety is cross-cutting by every test, and yet the deployed pattern treats it as application code.
The same test applies to LLM cost governance, model fallback, content filtering, agent-tool authorization, and audit. They are cross-cutting by every test. The default deployment pattern places them in the runtime anyway. The result is the AI version of pre-gateway microservices sprawl: every application validates prompts differently, every agent handles tool permissions differently, every MCP server makes its own authorization assumptions, every model integration has different rate limits and retry logic and cost ceilings, every team produces a different audit trail, and security cannot answer the simple question, what did this agent see, decide, call, and change?
This is the pre-API-gateway pattern, applied to AI. It violates all six conditions outlined above. It does not scale. It drifts on every deployment. It does not produce uniform compliance evidence. It hands attackers exploitable inconsistencies. It widens the supply chain’s attack surface. It does not work in polyglot stacks. And it cannot solve the AI-specific concerns it was deployed to solve, because each application solves them differently.
The Case Studies Are Already Public
The cost is not hypothetical.
In March 2026, attackers compromised the LiteLLM Python package. Two malicious versions, 1.82.7 and 1.82.8, were published to PyPI on March 24 after the maintainer's publishing token was stolen through an upstream supply chain compromise of the Trivy security scanner. Wiz Research observed LiteLLM running in approximately 36 percent of the cloud environments it analyzed. The package is downloaded more than three million times per day, and FutureSearch's analysis of BigQuery PyPI download logs found that the malicious versions were installed roughly 47,000 times before PyPI quarantined the package. Because the proxy ran inside the application process, the malicious payload had access to environment variables, API keys, cloud credentials for AWS, GCP, and Azure, Kubernetes configs, CI/CD secrets, and SSH keys. The investigation, based on reports by Snyk, Sonatype, Datadog Security Labs, and Trend Micro, traced the campaign to a group tracked as TeamPCP. Datadog Security Labs and other responders advised that any host or CI job that installed the affected versions should be treated as a full credential exposure event, not a routine package update gone wrong.
Tool poisoning is the MCP equivalent. First published by Invariant Labs and now identified in the emerging OWASP MCP Top 10 framework, currently in beta, tool poisoning exploits the fact that MCP tool descriptions are injected directly into the model context. A tool that appears benign by name can carry hidden instructions in its description that the model will follow. Academic threat modeling using STRIDE and DREAD identifies tool poisoning as the most prevalent and impactful client-side vulnerability in MCP today. The defense is not a smarter individual MCP server. It is an enforcement layer that inspects and authorizes every tool call before the model sees it.
The scale of exposure is no longer experimental. Wiz's 2026 report found that MCP servers were running in roughly 80% of analyzed cloud environments, with 5%of those environments running at least one internet-facing MCP server. Self-hosted AI agent technology was found in 57% of organizations. The footprint expanded faster than any infrastructure standard in recent enterprise computing memory, largely without architectural review.
Reliability data points the same way. Datadog's analysis of customer LLM call traces found that in February 2026, 5% of all LLM call spans returned errors, and roughly 60% of those errors were rate-limit failures from upstream providers. In March, rate-limit errors alone accounted for nearly 8.4 million failed spans. When fallback, retry, caching, and budget enforcement live in each application's code, each application owns its own resilience problem, and each solves it differently. Centralizing that logic, exactly as the API gateway pattern centralizes HTTP rate limiting, is the obvious response.
The Triple Gate Pattern: One Control Plane, Three Trust Boundaries
AI traffic in 2026 crosses three distinct trust boundaries, each with its own cross-cutting concerns.
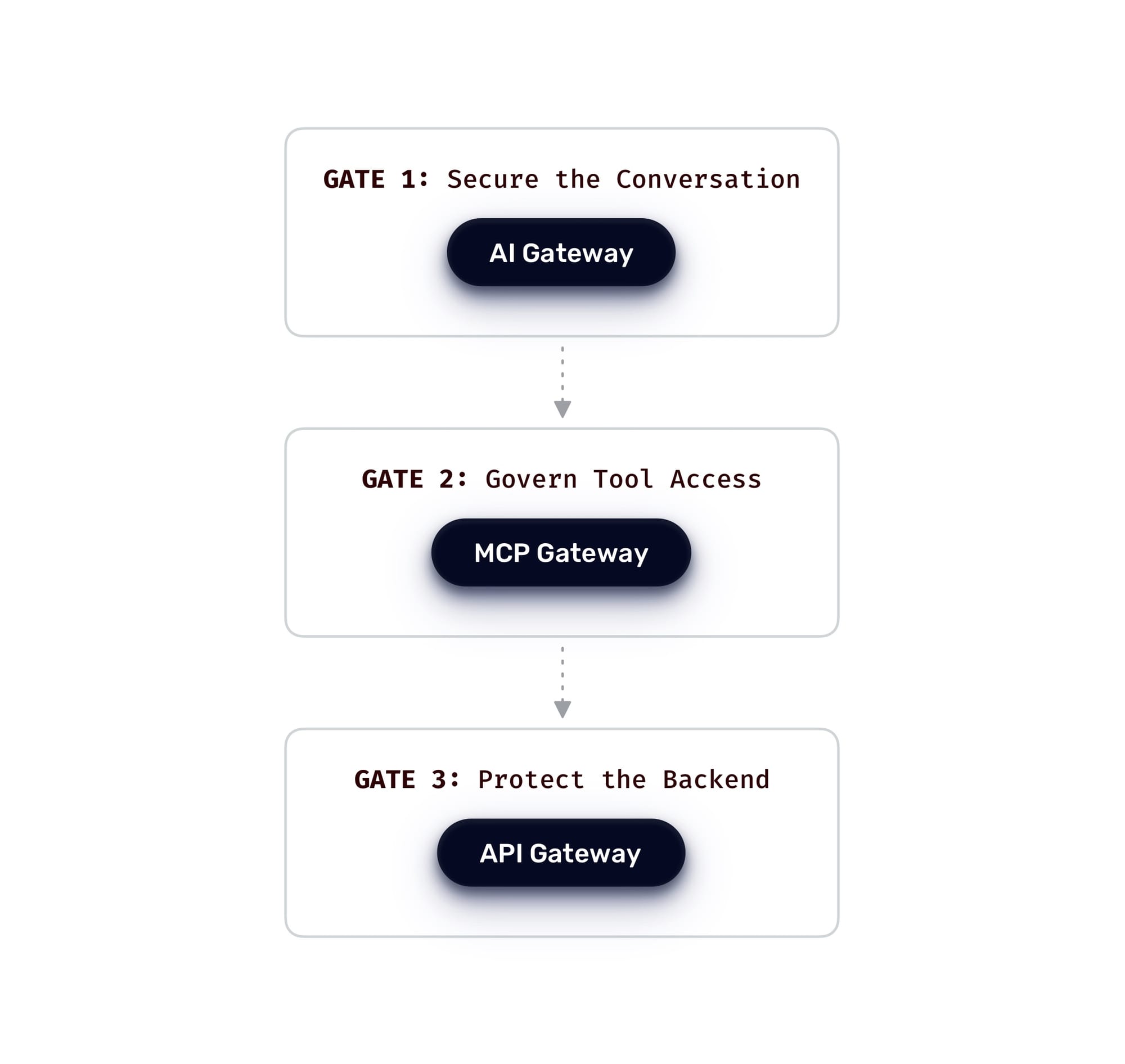
The conversation boundary, where prompts and completions move between users and models, is the AI Gateway's domain. Prompt injection defense, jailbreak detection, topic control, PII redaction, semantic caching, model routing, token-level cost control, model failover, and model observability all belong here. Every one of these passes the three-question test for cross-cutting.
The tool-and-action boundary, where agents discover MCP tools and invoke them with parameters, is the MCP Gateway's domain. Task-based access control, tool filtering, parameter validation, on-behalf-of token delegation, session routing, and tool-level audit belong here. Tool poisoning defense lives here as well, because the gateway is the only layer in the chain with full visibility into the tool description before the model sees it.
The backend-and-system boundary, where the result of all that activity becomes an actual API call into a system of record, is the API Gateway's domain. Authentication, function-level authorization, schema validation, rate limiting, WAF, and lifecycle governance all continue to belong here, exactly as they have for the past decade.
These three boundaries are the Triple Gate Pattern. They need to operate as one control plane, not three separate systems.
This is not the same as putting everything in the gateway. Each gate enforces the cross-cutting policy envelope at its trust boundary. The applications behind the gates still own their domain decisions: business rules, workflow logic, and the object-level authorization checks that depend on the relationship between the caller and the specific data being accessed. The gateway should enforce the shared runtime concerns. The application still owns the domain-specific ones. That distinction is what keeps the pattern useful rather than overreaching.
When each gate is implemented as application runtime code rather than infrastructure, the pattern fragments. The API gateway is in the infrastructure layer, where it has always been. The AI gateway is a library inside one team's Python service. The MCP gateway is a sidecar pattern built by another team last quarter, with different policy semantics and a different config language. The three gates do not see each other. The audit trail does not connect. A request that enters through the API gateway as an authenticated user X can emerge as a privileged service account at the MCP gateway because the application in between handled identity its own way. The cost-governance policy at the AI gateway is unaware of the rate-limit policy at the API gateway, because they are different systems run by different teams on different release cadences.
The compounding effect is operational. An LLM proxy sees the model interaction but not the agent actions that follow. An MCP proxy sees tool calls but not the LLM conversation that triggered them. An API gateway sees the inbound user request but loses sight of what the agent did downstream. Each layer knows part of the story. No one knows the full chain. When an incident occurs, the investigation has to stitch together logs from three systems with three different identity models, three different policy languages, and three different teams to find out what happened.
What security and platform teams actually need: one control plane, one declarative policy expressing what is allowed at each gate, one identity propagated across all three, one audit trail covering the full request chain, and one operational surface for incident response. That is the case for treating AI Gateway and MCP Gateway as infrastructure-layer concerns rather than application-layer libraries. The same case that the industry already accepted for the API gateway applies consistently to the new traffic types.
A Few Points That Deserve Their Own Spotlight
Supply chain placement is part of the cross-cutting concern surface. The LiteLLM incident is widely framed as a supply chain attack, which it was. It is also, more fundamentally, an architectural placement failure. A cross-cutting concern that had to be implemented somewhere was implemented inside every application's process space. The supply-chain attack succeeded because the proxy lived in the runtime. An infrastructure-layer gateway, deployed as a single hardened service that the platform team operates, has a fundamentally different attack surface than a Python library imported by every application team in the company. Both can be compromised. The blast radius is not the same.
Identity has to flow through the chain. An end user authenticates at the API gateway. The request hits an agent. The agent invokes an MCP tool. The tool calls a backend API. If the same identity does not flow end-to-end through this chain, the system either has to grant the agent broad service-account privileges, which violates least privilege, or invent application-level identity translation, which fragments yet again. Token delegation, on-behalf-of flows, and task-based access control at the gate layer are the mechanisms that keep this chain coherent. They cannot be implemented well as application code, because they require a privileged position in the request path.
Memory safety and language choice matter at the gate. CISA's January 2026 memory safety roadmap deadline, NSA and FBI guidance, and the EU Cyber Resilience Act all push critical infrastructure toward the adoption of memory-safe languages. The control plane sitting in front of every API, every LLM call, and every MCP tool invocation is critical infrastructure by any reasonable definition. The gate cannot be a place where C and C++ vulnerabilities still live.
Where to Go From Here
Cross-cutting concerns belong in a layer where they can be expressed once and enforced consistently. That is true today, in 2026, for the same reasons that made it true for HTTP traffic a decade ago, plus several reasons that did not exist then: AI-specific concerns, agent-driven callers, faster threat economics, and a much larger supply chain blast radius.
The API gateway pattern absorbed this lesson at the HTTP layer over the past decade. Production telemetry validated it. The pattern is now standard architecture, applied without much debate, because the costs of the alternative were paid out in public over many incidents.
The AI stack is now in the position the API stack was a decade ago. The architectural pressures are the same, the early warning signs are already on the public record, and the lessons are available to read. The LiteLLM compromise, tool poisoning attacks against MCP, the scattered guardrail-library deployment pattern, and the fragmented identity flow across LLM and agent traffic all point in the same direction. The Triple Gate Pattern, with API Gateway, AI Gateway, and MCP Gateway operating as a unified infrastructure-layer control plane, is the architecturally consistent response.
Cross-cutting concerns become dangerous when they are implemented locally but expected to behave globally. The teams that handle the AI infrastructure transition well will not be the ones with the most guardrails scattered across the most applications. They will be the ones whose runtime architecture governs every request, every prompt, every tool call, and every API behind it from a single, coherent control plane.
The principle holds. Agentic AI is making it concrete: runtime governance needs runtime enforcement, and runtime enforcement needs gates. The choice for teams building AI infrastructure in 2026 is which costs to absorb: the small, planned cost of getting the architecture right at the start, or the much higher costs of the API gateway era already documented when the same principle was learned in production. The data, case studies, and deployment patterns suggest that choice is closer at hand than it might feel.
Frequently Asked Questions
What is a cross-cutting concern, and how do I know if something qualifies?
A cross-cutting concern is behavior that needs to apply consistently across many parts of a system but does not belong to any one of them. Three tests identify it cleanly. First, the uniformity test: would the organization expect every team to implement this exactly the same way? Second, the domain knowledge test: does the implementation require knowing what the application does? Third, the blast radius test: when this behavior is wrong, is the failure systemic or local? If the answer is uniform, requires no domain knowledge, and fails systemically when wrong, it is cross-cutting and belongs at a shared enforcement layer, not inside each application.
Isn't a guardrail library good enough for prompt safety?
Guardrail libraries do what they claim at the function level. The architectural problem is placement. When five teams each import their own guardrail library with their own configuration, the organization has five policy rule sets drifting in five different directions. More fundamentally, a guardrail that lives inside the model's probabilistic reasoning loop depends on the model's decision to comply with it. That is a layer of defense. It is not enforcement. Enforcement requires an independent runtime boundary that the model cannot reason its way around.
What made the LiteLLM compromise so damaging, and could better security hygiene have prevented it?
Better hygiene at the package level would have helped at the margins, but the root cause was architectural. The proxy ran inside the application process, which meant that compromising one package version gave the attacker access to every credential the application held (e.g., API keys, cloud credentials, Kubernetes configs, CI/CD secrets). An infrastructure-layer gateway deployed as a single hardened service has a fundamentally different attack surface. Both can be compromised, but the blast radius is not the same. The LiteLLM incident is a supply chain story on the surface and an architectural placement failure underneath.
We already have an API gateway. Does that cover our AI traffic?
It covers the backend-and-system boundary—i.e., authentication, function-level authorization, schema validation, rate limiting—exactly as it always has. It does not cover the two new boundaries the AI stack introduces. The conversation boundary, where prompts and completions move between users and models, needs prompt injection defense, jailbreak detection, PII redaction, semantic caching, model routing, and token-level cost control. The tool-and-action boundary, where agents discover and invoke MCP tools, needs task-based access control, tool filtering, parameter validation, and tool poisoning defense. An API gateway was not built to inspect content at either of those boundaries. Extending the same architectural principle to all three trust boundaries is what the Triple Gate Pattern addresses.
How does identity work across the full agent request chain?
An end user authenticates at the API gateway. The request hits an agent. The agent invokes an MCP tool. The tool calls a backend API. If the same identity does not flow end-to-end through that chain, the system either grants the agent broad service-account privileges, which violates least privilege, or invents application-level identity translation, which fragments governance again. Token delegation, on-behalf-of flows, and task-based access control at the gate layer are the mechanisms that keep the chain coherent. They require a privileged position in the request path that application code cannot reliably hold.
What is tool poisoning and why can't individual MCP servers defend against it?
Tool poisoning exploits the fact that MCP tool descriptions are injected directly into the model context. A tool that appears benign by name can carry hidden instructions in its description that the model will follow, including redirecting actions, exfiltrating data, or chaining to unauthorized tool calls. Individual MCP servers cannot defend against this because the attack targets the model reading the description, not the server serving it. The only layer with full visibility into the tool description before the model sees it is a gateway sitting between the agent and the MCP server catalog. That is where tool poisoning defense has to live.


