

Microservice-based applications are more efficient, scalable, and resilient than monolithic applications. They allow organizations to deploy at high velocity across hybrid and multi-cloud infrastructures.
Microservice architectures are also far more difficult to manage — especially at scale. Service-to-service communication is critical for the resilience of distributed applications but becomes increasingly complex as you add more Kubernetes clusters. Simplifying all this complexity is the job of a service mesh.
What is a service mesh?
A service mesh is a piece of software that adds security, observability, and reliability to the platform level of a microservices application. It is a dedicated layer within the infrastructure that enhances communication.
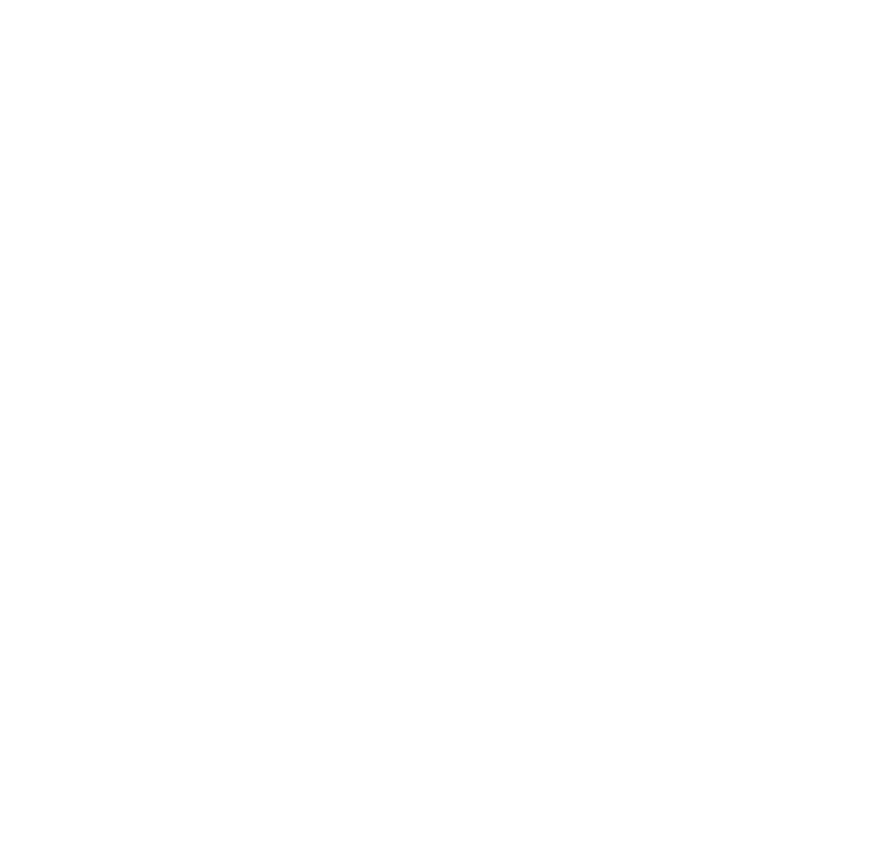
Within the service mesh, there is the control plane and the data plane. The control plane sits just above the data plane and is where the user configures the actions of proxies. It is essentially the management side of the service mesh.
Within the data plane, individual proxies are typically attached to nodes or applications (this would be called the sidecar pattern, illustrated further down). They intercept incoming and outgoing application requests, allowing communication between microservices — often referred to as east/west traffic management. It’s these connected proxies that create the mesh between your services.
In addition to connecting your services, the proxies also provide an array of features that add security, observability, and reliability to the platform. The applications themselves do not need to be modified, as the features are added at the platform level. Some of these features include:
Security
- mTLS (mutual Transport Layer Security) is used to authenticate both parties and secure/encrypt the communication with TLS. Each party verifies the other’s identity, meaning only parties in the same realm can communicate.
- ACLs (access control lists) are used to define access control policy rules, in order to authorize traffic between services.
Observability
- Tracing means figuring out what is happening with the flow of requests. For example, it allows you to know that a request passing through service A will then be forwarded to service B to obtain data or perform an action.
- Metrics on service-to-service communication are essential for pinpointing problems as they occur.
Reliability
- Rate limiting means controlling the rate of requests between services to distribute traffic and prevent certain services from becoming overwhelmed while others remain idle.
- Retrying enables an application to retry an operation in the expectation that the operation will eventually succeed.
- Circuit breaking prevents an application from performing an operation that’s likely to fail.
How is a service mesh different from an API gateway?
A service mesh handles internal traffic between services inside a cluster, and the proxy is deployed alongside the application. In contrast, an API gateway handles external traffic coming to a cluster — often referred to as north/south communication. API gateways often include similar features, but they are not as integrated into the application. Features are exchanged between client/gateway, not between applications.
What are the benefits of a service mesh?
Service meshes allow applications to focus on business value only. Microservices can remain distributed and isolated while still communicating. They can benefit from out-of-the-box features while remaining lightweight.
These benefits make service meshes essential for cloud native infrastructures with many microservices as well as infrastructures that also have legacy applications that cannot be changed. They also enable DevOps teams to take full advantage of Kubernetes, configuring, and scaling multi-cluster applications across hybrid and multi cloud environments.
The service mesh landscape
There are currently many solutions for service meshes on the market. They differ wildly in their approach, as well as in the proxies they use. As the service mesh landscape is so heterogeneous, the Service Mesh Interface (SMI) was created to define a common standard that can be implemented by a variety of providers. It enables flexibility and interoperability and covers most service mesh capabilities. The SMI gives innovation to providers and some standardization to end users.
The different types of service mesh architecture
Service meshes rely on one of two basic proxy architectures — sidecar or host/node proxies. Let’s discuss the two architectures.
The sidecar proxy architecture
With the sidecar architecture, a proxy is attached to each application to intercept requests. The proxy injects the features seen earlier into the platform, enabling security, observability, and reliability. This method is invasive, as the deployment objects and network routing rules (using iptables, for example) need to be modified by the service mesh solution.
The advantage of the sidecar architecture, however, is the control. As the proxy lives closer to the application, end-users have more access to in-depth observability metrics and have an easier time automating the flow of traffic. But this advantage comes at a price.
Adding sidecar proxies to each service adds more complexity to your application’s architecture. It becomes more difficult to understand if something has gone wrong or is misconfigured in networking rules. Sidecar proxies also require certain privileges (such as an init container with NET_ADMIN capabilities), and this can lead to security vulnerabilities.
Most service meshes use sidecar proxies, including Istio, Linkerd, and Kuma. These solutions are feature-rich and can become expensive due to the number of proxies required, and operational complexity.
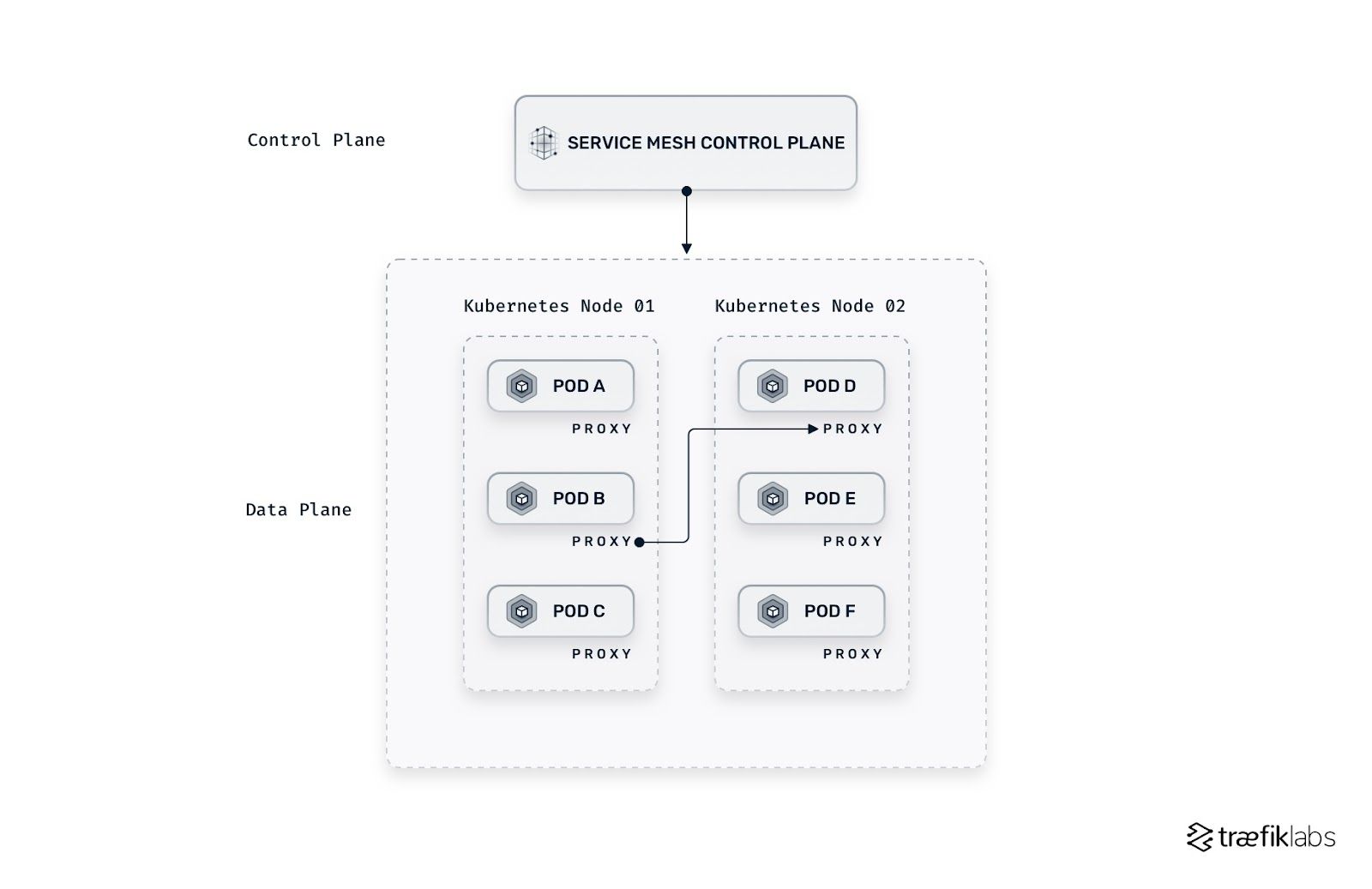
The host/node proxy architecture
With the host/node architecture, the proxy is attached to each Kubernetes node instead of each application. Traefik Mesh follows this architecture and uses Traefik Proxy as the reverse proxy. Fewer proxies are required, making the service mesh simpler and less costly to operate.
This type of architecture is non-invasive. Instead of invasively modifying routing tables, the user calls the name of a service and redirects it to the correct node through the DNS. SMI specifications are implemented. The application does not need to be modified. The features stay in the service mesh layer, keeping the applications lightweight while also secure, observable, and reliable.
Simplicity vs. complexity
Service meshes are complex solutions to complex problems. For that reason, they are not always needed. Some microservice-based applications aren’t ready for a complex, full-featured service mesh and would benefit from one that is simpler and provides most of the benefits but with fewer administrative costs.
The host/node architecture simplifies the service mesh and is ideally suited for organizations that don’t need an elaborate feature set. Traefik Mesh, for example, is a straightforward service mesh that is easy to configure. It grants visibility and management of the traffic flow within Kubernetes clusters — with a fraction of the operational cost and complexity required by sidecar architectures. It also allows organizations to scale the number of microservices without assuming the cost of adding more proxies.
Check out the Traefik Mesh documentation for a complete description of its features and capabilities.
For organizations that want simplicity but a more robust mesh, some solutions (like Traefik Enterprise) bundle the service mesh with an enterprise-grade ingress controller and API gateway.
Check out the Traefik Enterprise documentation for a complete description of its features and capabilities.
The benefits of a service mesh make it worth considering, particularly if you’re scaling microservice-based applications. Taking the time to review your application and understand its needs and direction will help you determine the type of service mesh and level of complexity that’s right for your project.
