

As the need for internet services intensifies, companies are rapidly scaling their cloud infrastructures by deploying more and more clusters across a broadening surface. Large enterprises today often maintain hundreds of clusters, and many have learned the hard way that it is far easier to add clusters than it is to manage the scaled system. As an architecture grows, its operational difficulty compounds.
For large enterprises deploying at scale, it is simply not an option to manually deploy all clusters. Tools and processes would be fragmented and built on top of one another. Errors and inconsistencies would be inevitable. DevOps teams would be stretched thin, and their work would show for it. We would see what is often called a ‘spaghetti infrastructure.’ GitOps is the preventative medicine for such chaos.
What is GitOps?
GitOps is a modern, cloud native way of managing Infrastructure as Code. It is the cloud’s declarative way of managing environments. It is an operating model that improves efficiency, reliability, and scalability. There are four key principles of GitOps.
The desired state of the infrastructure is expressed declaratively.
GitOps takes a declarative not imperative approach to computing. With imperative computing, the user defines the goal as well as the exact steps to take when reaching that goal. With declarative computing, the user defines the desired state and sends a solution through what is known as a reconciliation loop to achieve the goal.
Declarative computing is more efficient for an organization as the user has fewer parameters to define. It’s also innately well-suited to the Kubernetes ecosystem, as Kubernetes itself is a declarative system.
The desired state is stored in a version of truth that enforces immutability.
With GitOps, the desired state declared by the user is stored in a single source of truth. It is called GitOps because the single source of truth is centralized in a Git repository. Any change made to the state of infrastructure is processed through that Git repository. This enforces immutability, as the containers will always match the configuration specified in the single source of truth. Immutability ensures all containers are identical or almost identical, leading to deployments that are safer and more repeatable. It is a core component of containerized systems.
Configuration changes are pulled automatically from a source of truth and applied to clusters.
Configuration changes are not pushed by the single source of truth, they are pulled automatically from the single source of truth and applied to clusters. Once you create and commit changes to the main Git repository you use to store the code of your infrastructure, you use a tool to apply the configuration changes directly into your containers. The most popular tools to use are Flux and ArgoCD, both of which connect with a tool called Kustomize that applies changes in the correct order and lets you create a base environment with overlays.
Configuration changes are continuously reconciled.
In GitOps, agents are continuously observing the desired state defined in the main Git repository and applying that desired state to the entire infrastructure. In traditional CI/CD, automation is usually initiated by pre-set triggers. In GitOps, reconciliation is continuous as it is triggered by any divergence from the desired state declared in the main Git repository. This further enforces immutability.
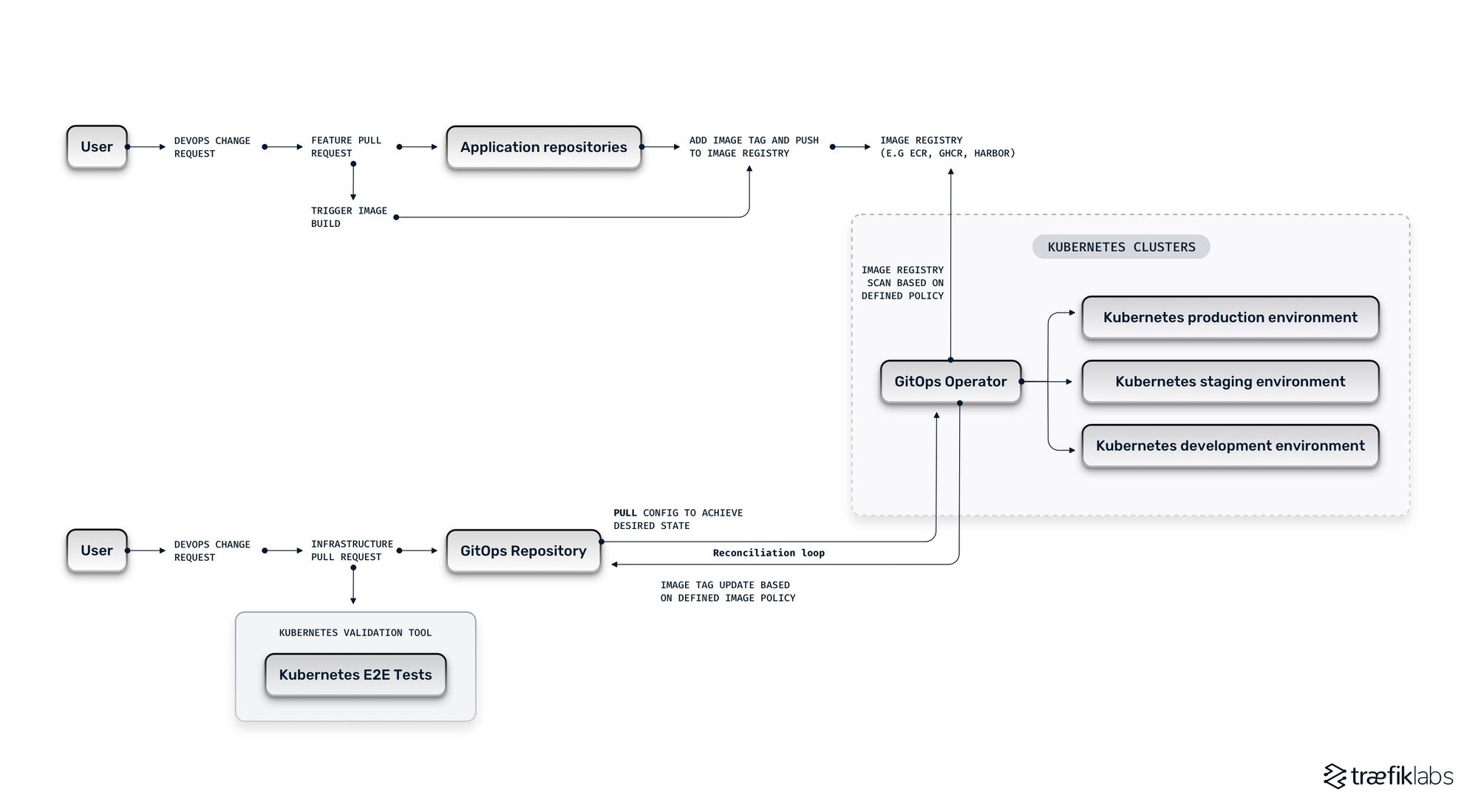
The difference between GitOps and DevOps
DevOps is a very broad term that essentially refers to a culture of collaboration that helps both development and operations teams achieve goals through the use of tools and processes. GitOps is a skill and an approach to managing infrastructure that encourages collaboration and therefore contributes to DevOps.
As GitOps centralizes configuration changes in a main repository, it facilitates collaboration. All team members can view the state of an infrastructure, check any changes that were made weeks or months in advance, and contribute to projects. It doesn’t necessarily make sense to use GitOps if you’re producing something that will only be around for a hot minute and that your teammates wouldn’t contribute to. Without GitOps, the configuration file is maintained on your local computer and is not accessible to your teammates. With GitOps, you push the configuration file to Git, your teammates can pull it to their computer to make changes as needed and push those changes back to Git, and Flux or ArgoCD pulls the configuration and applies the desired state to other clusters. As such, GitOps facilitates collaboration and is a useful skill for DevOps teams.
How to get started with GitOps
There is no minimum size of architecture to use GitOps, and it is always a good practice to start from the beginning with a GitOps approach. Especially if you are managing environments with two or more engineers, you would benefit from using GitOps to ensure effective collaboration. GitOps lets you know what changes your teammates have committed. It helps you avoid configuration drift, which is a common mistake that happens when an infrastructure is managed manually. With GitOps, you can be certain that everything is completely up to date.
If you’re thinking about using GitOps down the line, start using it from the beginning. Download Flux or ArgoCD, look at the documentation and implement GitOps in your test environment. That way, you will learn how it works and lay the groundwork for scaling your deployments with GitOps.
Traefik Proxy makes it easy to manage traffic in GitOps workflows. Check out this article to learn how Traefik Proxy and Flux can work together to help you implement GitOps principles, so you can easily maintain multiple configurations in Kubernetes.
References and further reading
- Automating at Scale with GitOps and a Declarative Approach
- How to Deploy Traefik Proxy Using Flux and GitOps Principles
- Traefik GitOps with Flux
- Taming Multiple Traefik Deployments with a GitOps Strategy
- How to Manage the Edge and Internal Ingress at Scale with Traefik and GitOps
