One Gateway. Three Estates. Zero Compromises.


How Nutanix and Traefik Labs Are Unifying Application Delivery Across VMs, Containers, and AI.
A joint perspective from Nutanix and Traefik Labs.

The infrastructure world is in the middle of a tectonic shift, and it's not a single earthquake. It's three hitting at once.
Enterprise IT teams are navigating a VMware displacement wave triggered by the Broadcom acquisition. They're managing the coexistence of legacy applications on virtual machines alongside modern microservices running in Kubernetes. And they're under pressure to operationalize AI, embedding inference directly into production applications, not as a science experiment but as a business-critical capability.
Each of these shifts alone would be a multi-year transformation. Together, they're redefining what enterprise infrastructure must look like.
Add to this the rise of sovereign computing. Financial services firms bound by data residency mandates. Healthcare organizations navigating patient data regulations across geographies. Government agencies requiring air-gapped deployments. These organizations can't simply lift and shift to hyperscalers. They need infrastructure that keeps data, models, and governance under their control, on their terms, in their locations.
Here's what makes this moment unique: AI is not a separate workload category. It's becoming embedded inside every application. A single user action, logging into a banking app, checking an account balance, initiating a transfer, can touch a containerized frontend, a VM-hosted core system, and an AI inference endpoint within the same request flow. The user doesn't know. The user doesn't care. They just expect it to work.
The question isn't whether enterprises will run workloads across VMs, containers, and AI infrastructure simultaneously. They already do. The question is whether they have a unified way to route, observe, secure, and govern traffic across all three.
The Real Challenges Behind the Buzzwords
When we talk to enterprise infrastructure teams, the conversation quickly moves past technology preferences and into operational reality.
VMs and containers must coexist for years. The notion that every organization will "just move to Kubernetes" ignores the reality of core banking platforms, ERP systems, mainframe-adjacent workloads, and thousands of VM-based applications that will run for another decade. These aren't candidates for re-architecture. They're candidates for better management. At the same time, every new application, every new capability, is being built cloud-native. Infrastructure teams don't get to choose one world. They have to operate in both.
Complexity is the real enemy, not any single vendor. The skills gap in enterprise IT is well documented. Kubernetes expertise remains scarce. Networking teams trained on traditional load balancers are being asked to manage service meshes. Security teams need policy enforcement that spans environments they barely understand. Every additional tool, console, or abstraction layer compounds this problem. Organizations need fewer moving parts, not more.
Escaping one lock-in shouldn't create another. The VMware migration conversation is often framed as "pick a new hypervisor." But the smarter organizations are thinking beyond that. They want strategic decoupling: the ability to move workloads between infrastructure providers without rearchitecting their application delivery, security policies, or observability pipelines. The governance layer must be portable, even if the compute layer changes.
Day 0 preparation is more important than Day 1 migration. Most migration solutions focus on Day 1: getting workloads moved. But the riskiest moment in any migration is the cutover itself, when application traffic must shift from old infrastructure to new without disruption. Organizations that couple application identity directly to infrastructure identity (hardcoded IPs, DNS-dependent routing, infrastructure-specific load balancers) face downtime windows, DNS propagation delays, and split-brain risks every time a workload moves. The smarter approach is to decouple the application layer from the compute layer before migration begins, so the underlying infrastructure becomes interchangeable. And then comes Day 2 and beyond: who handles traffic management across a heterogeneous environment? How do you enforce consistent rate limiting, authentication, and access policies when workloads span VMs and Kubernetes? What happens when you need to add an AI inference call into an existing application flow without redesigning the entire pipeline?
AI insertion demands infrastructure readiness. The organizations best positioned to operationalize AI are not the ones with the most GPUs. They're the ones that already have unified ingress and governance across their infrastructure. If you can't consistently route, observe, and policy-govern traffic across VMs and containers today, you can't add AI inference as a third estate tomorrow. AI readiness is a side effect of good infrastructure, not a separate initiative.

Unified Application Intelligence: The Nutanix and Traefik Labs Joint Solution
Nutanix and Traefik Labs have built a joint solution designed around a simple but powerful principle: one application intelligence layer that follows your workloads, regardless of where they run.
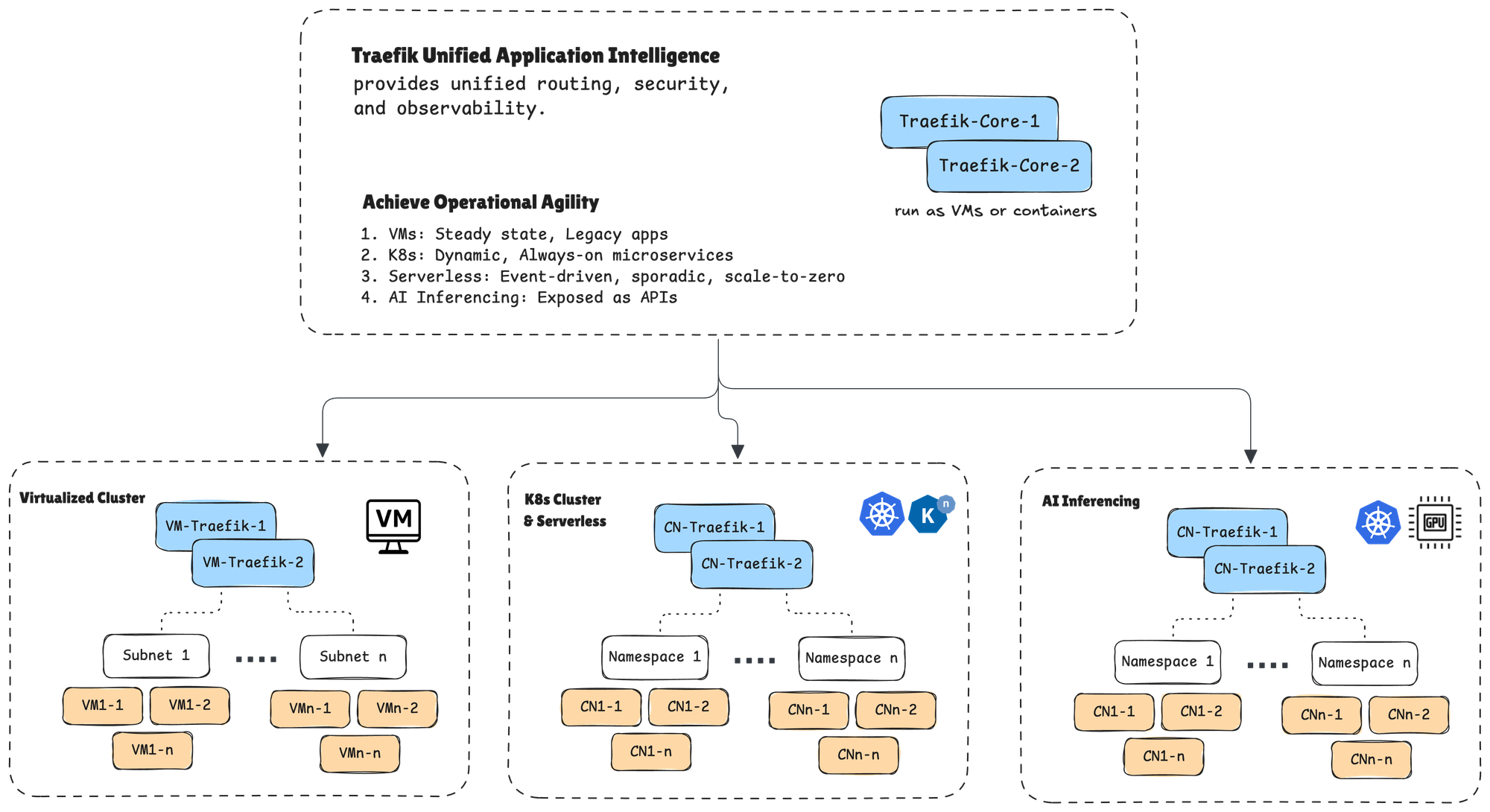
Nutanix provides the foundational compute, storage, and Kubernetes platform. Traefik provides the unified Layer 7 ingress, routing, and governance that spans across it all. Together, they deliver something neither can offer alone: a consistent application delivery experience across VMs, containers, and AI workloads, managed from a single operational plane.
Here's what this looks like in practice.
Unified ingress across three estates. Traefik provides a single entry point for all application traffic, whether it's destined for a virtual machine on Nutanix AHV, a containerized service on Nutanix Kubernetes Platform (NKP), or an AI inference endpoint running on GPU-accelerated infrastructure. One gateway. One set of policies. One place to observe and troubleshoot. No stitching together separate load balancers, API gateways, and AI-specific proxies.
A lightweight footprint from edge to cloud. Traefik's single binary architecture means it runs everywhere: on a Nutanix cluster in a data center, on a small edge appliance at a retail location, or on a GPU node processing inference requests. There's no heavyweight sidecar tax or complex dependency chain. This matters enormously for organizations running Nutanix at the edge for use cases like manufacturing, retail, and healthcare imaging.
Default ingress in NKP. Traefik ships as the default ingress controller in Nutanix Kubernetes Platform. This isn't a marketplace listing or a "works with" certification. It's an engineering decision by Nutanix to make Traefik the native traffic management layer for every NKP deployment. Customers get enterprise-grade ingress out of the box, with a seamless upgrade path to advanced capabilities.
A clear upgrade path without rip-and-replace. Organizations can start with the open-source Traefik Proxy, which already powers millions of deployments worldwide with over 3.4 billion Docker Hub downloads, and upgrade to enterprise-grade capabilities as needs evolve: API gateway functionality, AI gateway with model routing and token-level governance, MCP gateway for agentic AI frameworks, and full API lifecycle management. The same ingress layer grows with the organization.
Under the Hood: How the Integration Works
The Nutanix and Traefik Labs integration goes deeper than simple co-deployment. It's a set of native integrations that make the unified ingress story operational.
Auto-Discovery Across AHV Virtual Machines
Traefik integrates directly with Nutanix Prism Central to auto-discover virtual machines and their associated services. When a new VM spins up or an existing service changes, Traefik detects it automatically and attaches the appropriate routing rules, security policies, and traffic management configurations. No manual reconfiguration. No configuration drift between what's running and what's being managed. This is critical for organizations managing hundreds or thousands of VMs as part of a VMware migration. As workloads land on AHV, they're immediately visible to and governed by Traefik.
Native Kubernetes Integration on NKP
On the Kubernetes side, Traefik integrates natively with NKP using standard Kubernetes Ingress resources and Traefik's own IngressRoute CRDs. Container workloads are auto-discovered as pods scale up and down, services are registered dynamically, and routing policies are applied consistently. Because Traefik is the default ingress in NKP, there's no separate installation or configuration step. It's ready from the first cluster deployment.
Complementing Flow Networking at Layer 7
Nutanix Flow Virtual Networking and the newly released Flow CNI provide robust Layer 4 network segmentation, microsegmentation, and connectivity across the Nutanix stack. Traefik complements this with Layer 7 application intelligence: content-based routing, header inspection, path-based policies, rate limiting, authentication, and API-level governance. Think of it as two layers working in concert. Flow handles the network plumbing and segmentation. Traefik handles the application-aware traffic decisions. Together, they provide defense in depth without requiring organizations to choose between network-level and application-level controls.
AI Workload Routing and Governance
For AI inference workloads, whether running on GPU-accelerated clusters on-premises, at the edge, or across hybrid environments, Traefik provides the same Layer 7 governance it applies to VMs and containers. This includes intelligent model routing (directing requests to the right model version or endpoint based on content, headers, or load), token-level rate limiting to manage expensive GPU resources, and security guardrails that ensure AI endpoints are subject to the same authentication and access policies as every other service. The key architectural insight: AI inference is just another endpoint behind Traefik's unified ingress. It doesn't need a separate gateway, a separate policy framework, or a separate observability pipeline.
What This Looks Like: A Real Application Flow
Consider a banking application, a pattern representative of what we see across financial services, healthcare, and other regulated industries.
A customer opens their mobile banking app. That initial request hits Traefik and is routed to the React frontend running as a containerized service on NKP. The user logs in, and Traefik routes the authentication request through middleware enforcement to identity services, also on NKP. Once authenticated, the dashboard loads account data. Traefik routes that request to the core banking platform, a VM-based system running on Nutanix AHV that has served the institution reliably for years. The user initiates a funds transfer. Before the transaction is processed, Traefik routes a fraud detection request to an AI inference endpoint for real-time scoring. The check passes, and Traefik routes the final transaction request back to the core banking system on AHV to complete the transfer.
Five steps. Three infrastructure types. One gateway managing the entire flow.
The user experienced a seamless interaction. The infrastructure team manages one ingress layer with one set of policies. The security team has one audit trail. The compliance team has one governance framework. And when the next capability gets added, whether it's a new AI model for personalized recommendations or a containerized notification service, it plugs into the same architecture without re-plumbing.
The Time to Act Is Now
For organizations evaluating their infrastructure strategy, three use cases make the Nutanix and Traefik Labs joint solution immediately actionable.
Migrate: Start with Day 0, not Day 1. Most migration strategies focus on Day 1: the moment a VM moves from one hypervisor to another. But the smartest organizations start at Day 0, before a single workload moves, by deploying Traefik as the unified ingress layer in front of their existing VMware environment.
Why? Because the riskiest part of any migration isn't moving the VM. It's maintaining application availability during and after the move. When application traffic is coupled directly to the infrastructure, a VM migration means DNS changes, propagation delays, potential downtime windows, and user-visible disruption. But when Traefik sits in front as the application's ingress layer, the VM becomes a backend detail. You move it from ESXi to Nutanix AHV. Traefik auto-discovers the new location via Prism Central integration. Traffic keeps flowing. The user never knows the underlying substrate changed.
This is the architectural principle that makes migration resilient by design: decouple the application identity from the infrastructure identity. Traefik owns the routing, the policies, and the traffic management. The hypervisor becomes interchangeable. No split-brain risk during cutover. No "please allow 24-48 hours for DNS propagation." No gap between migration and governance. The same ingress layer that manages your VMs on ESXi today manages them on AHV tomorrow and manages your containers and AI workloads the day after that.
Modernize: Decompose monoliths at your own pace. As applications evolve from monolithic VMs to containerized microservices on NKP, Traefik provides seamless traffic shifting between the old and new. Route 90% of traffic to the legacy VM. Shift 10% to the new container-based service. Validate. Adjust. No big-bang cutover. No separate tooling for each environment. The migration from VM to container happens behind the same gateway, with the same policies, at whatever pace the business requires.
AI-Enable: Insert intelligence without re-architecture. When the time comes to add AI capabilities, whether fraud detection, recommendation engines, document processing, or predictive analytics, Traefik's AI and MCP Gateway provides the same routing, governance, and observability for inference and MCP endpoints that it already provides for VMs and containers. There's no new gateway to deploy, no new policy framework to learn, and no new blind spot in your observability pipeline.
These aren't three separate journeys. They're stages of a single infrastructure evolution: prepare at Day 0, migrate at Day 1, modernize at your own pace, and AI-enable when the business demands it. The organizations that put the right application intelligence layer in place before the first VM moves will navigate each stage faster, with less risk, and with fewer late-night fire drills.
The infrastructure world has shifted. VMs, containers, and AI workloads aren't converging someday. They've already converged, inside your applications, inside your request flows, right now. The only question is whether you have one gateway managing all of it, or three separate tools creating three separate problems.
Nutanix and Traefik Labs joint solution chose one gateway. We think you should too.
To learn more about the Nutanix and Traefik Labs joint solution, visit https://traefik.io/solutions/nutanix-and-traefik.
To see the integration in action, join us at .NEXT 2026 in Chicago April 7th- 9th.


