Ingress NGINX Migration Guide (1 of 3): Measure Twice, Cut Once


Every migration story starts the same way: with a team staring at a production cluster, a long changelog of annotations, and a ConfigMap nobody has touched in three years. The gap between "we should migrate off Ingress NGINX" and "we know exactly what to do Monday morning" feels enormous. Opaque. Risky. Expensive.
It isn't.
In the vast majority of clusters I've seen since we started helping teams move off Ingress NGINX, 99% of the migration is mechanical: the annotations translate directly, the ConfigMap settings have an obvious Traefik equivalent, and the cutover is a matter of shifting traffic route by route. Only about 1% of a typical deployment actually requires human judgment. The hard part isn't doing the work. The hard part is knowing, before you start, which 1% deserves your attention.
That's what an audit is for. And it's the first thing you should do, before you install Traefik, before you touch a single Ingress resource, before you write a migration plan.
This is post 1 of a 3-part series on migrating from Ingress NGINX to Traefik, published alongside the Traefik v3.7 GA. We've broken the series into three steps:
- Audit (this post): inventory your annotations and translate the NGINX ConfigMap.
- Install: deploy Traefik with Helm next to your existing NGINX controller.
- Migrate: cut over route by route, using IngressClass routing, L4 TLS pass-through, and a blue-green pattern.

The Real Cost of Skipping the Audit
The instinct when a project is under deadline pressure is to start moving. Install the new controller. Flip the first route. Fix things as they break. I understand the appeal. I've shipped enough infrastructure to know that "just start" works, sometimes.
This is not one of those times.
Ingress NGINX accumulates complexity in two places that are easy to overlook. The first is annotations on individual Ingress resources, which have grown to several hundred over the years. Most teams use a handful; a few teams use dozens; almost nobody has a complete inventory. The second is the controller ConfigMap, which quietly sets cluster-wide defaults for timeouts, TLS policy, body sizes, logging formats, and a long tail of NGINX-specific tuning that your application teams have never seen and would not recognize.
Skip the audit and these two surfaces bite you at the worst possible moment: after you've already put Traefik in the traffic path. A missing annotation mapping causes a silent behavior change for one team. A forgotten ConfigMap setting breaks TLS for a specific client. You roll back under pressure, lose trust, and the migration stalls for a quarter.
The audit is not a box-ticking exercise. It's the difference between a migration that takes an afternoon and one that takes a fiscal year.
Why Grep is Not an Audit
The obvious temptation is to kubectl get ingress -A -o yaml | grep annotations and call it a day. Don't. That approach fails on three fronts.
First, it tells you which annotations exist but not which ones actually matter. An annotation that Traefik supports natively is a non-event. An annotation that requires a new middleware is a small piece of work. An annotation with no direct equivalent is a conversation with the team that owns that Ingress. Grep cannot distinguish between these three, and treating them as equivalent is how migrations slip.
Second, it ignores the ConfigMap entirely. The ingress-nginx-controller ConfigMap is where your proxy-body-size, your ssl-ciphers, your hsts-max-age, and your use-proxy-protocol live. None of these appear on any Ingress resource. None of them will show up in a grep of your Kubernetes manifests. All of them affect production behavior.
Third, it produces a list, not a plan. A list of annotations is not actionable until someone sits down and maps each one to its Traefik equivalent, identifies gaps, and decides what to do about them. That work takes hours or days depending on cluster size. Worse, it gets redone every time a new engineer picks up the project.
This is exactly the kind of problem that tooling solves well and humans solve badly.
The Two-Step Audit
Here is the approach we recommend, and it has a deliberate order: Ingress annotations first, ConfigMap second. Both matter. Doing them in this sequence means you can scope the work and start planning before you touch the controller itself.
Step 1: Audit Your Ingress Annotations with the Migration Tool
We built ingress-nginx-migration, an open-source CLI that connects to your cluster and analyzes every Ingress resource in the namespaces you choose (or all of them, by default). It serves an interactive HTML report at http://localhost:8080.
Install and run it against your live cluster:
curl -sSL https://raw.githubusercontent.com/traefik/ingress-nginx-migration/main/scripts/install.sh | bash
ingress-nginx-migration --kubeconfig ~/.kube/config
The tool needs read-only access (list, get, watch) on ingresses and ingressclasses. Nothing else. It never modifies your cluster.
The report classifies your annotations into four buckets:
- Vanilla: Ingresses that use no Ingress NGINX-specific annotations at all. They migrate as-is, on any recent Traefik version. For many clusters, this is a surprisingly large share.
- Supported: Ingresses whose every nginx annotation has a Traefik equivalent. These also migrate as-is, with no YAML rewriting. The report tells you the minimum Traefik version each annotation requires (v3.6, v3.7, or Traefik Hub for ModSecurity), so you know exactly which version to deploy.
- Unsupported: Ingresses that use at least one annotation Traefik does not yet support. The report lists those annotations and their frequency across your cluster, so you can quickly see whether you are looking at a couple of edge cases or a load-bearing pattern that needs a workaround.
- Invalid: Annotations the tool does not recognize at all - neither in the supported list nor in the known-unsupported list. These are typically typos, custom extensions, or annotations specific to a fork. They get their own tab in the report so you can review them and clean up before the migration rather than during it.
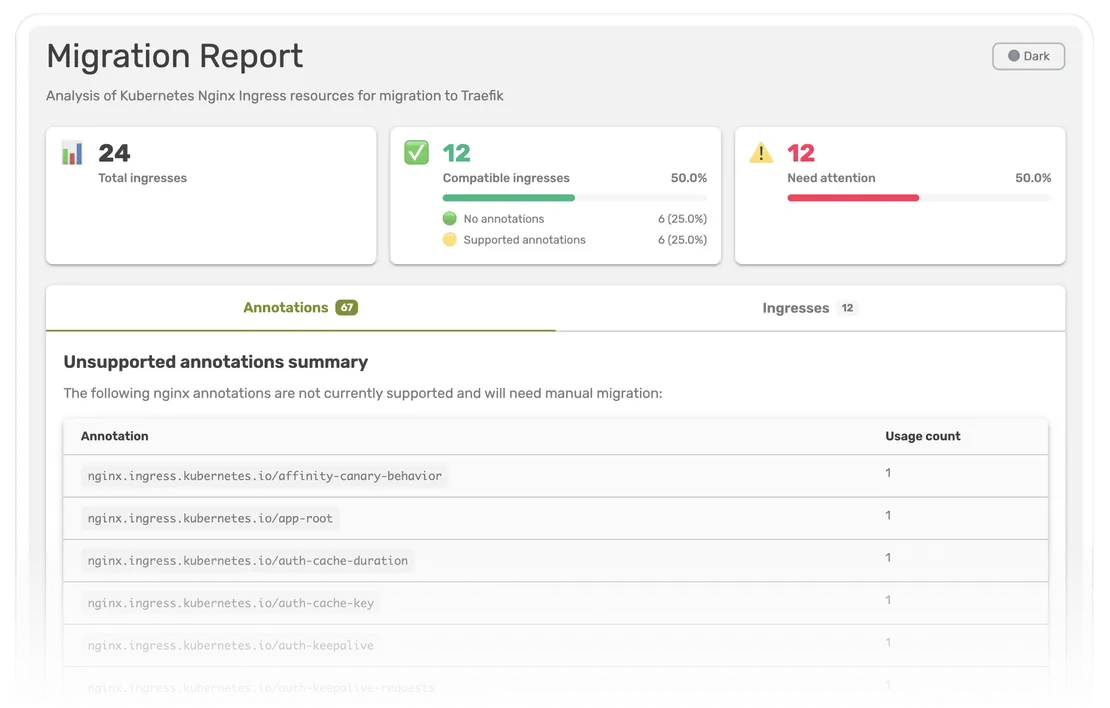
In a matter of minutes, the tool turns "hundreds of Ingresses in production" into a prioritized queue. You know exactly which resources migrate seamlessly today, what minimum Traefik version covers the bulk of your fleet, and which Ingresses need a closer look before you touch them.
If you choose to share your report with us via the "Share Report" button (anonymized by design - only counts and annotation names, never resource names, namespaces, or configurations), you also help us prioritize which annotations we add support for next. Many of the 80+ annotations now supported by Traefik v3.7 were prioritized from data that users sent us through exactly this channel.
Step 2: Translate your ConfigMap
Once you know the state of your Ingress annotations, turn to the other half: the controller ConfigMap. The full mapping table lives in the Ingress NGINX ConfigMap migration guide.
In Ingress NGINX, the ConfigMap is a single cluster-wide configuration layer. In Traefik, the same behavior is split across four surfaces, each with a clear purpose:
- The
providers.kubernetesIngressNGINXstatic configuration, for Ingress NGINX compatibility defaults likeproxyBodySize,proxyConnectTimeout, andproxyBuffering. - EntryPoints, for listener behavior like HTTP-to-HTTPS redirection and PROXY protocol.
- Dynamic
tls.optionsand HTTP middlewares, for TLS policy, HSTS, and header behavior. - Traefik access log configuration, for request logging.
This split is intentional. Each surface has a single, well-defined responsibility, which makes Traefik's behavior easier to reason about per route. It also means that when you migrate, you rarely need to translate a ConfigMap setting to a single equivalent. You translate it to the right surface.
Start by exporting what you actually use today:
kubectl get configmap ingress-nginx-controller -n ingress-nginx -o yaml
Most keys fall into one of three categories. The first is the direct-mapping keys: proxy-connect-timeout, proxy-body-size, client-body-buffer-size, proxy-next-upstream, custom-http-errors, and similar. These have a one-to-one Traefik equivalent under providers.kubernetesIngressNGINX. The only gotcha is unit conversion: NGINX accepts values like 16k or 1m, Traefik expects raw bytes or integer seconds.
The second category is the cross-cutting keys: ssl-redirect, ssl-protocols, hsts, use-proxy-protocol. These don't belong on the provider; they belong on entryPoints, TLS options, or a headers middleware attached cluster-wide. This is where Traefik's per-surface model pays off: a headers middleware attached to an entryPoint gives you a cluster-wide HSTS default, but you can override it per-route without editing a central ConfigMap and rolling the whole controller.
The third category is the drop-it keys: worker-processes, worker-cpu-affinity, Lua shared dict settings, main-snippet, http-snippet, and their friends. These are NGINX internals. Traefik doesn't expose them because Traefik isn't NGINX. If you find one of these in your ConfigMap, translate the intent, not the directive. Ask yourself what behavior the team actually wanted, and configure that behavior in Traefik.
The complete, section-by-section translation table is in the ConfigMap migration step of the guide. It covers every ConfigMap key we've seen in production clusters and tells you exactly which Traefik surface takes over.
What the Audit Gives You
When you finish the two-step audit, you have three artifacts:
- A categorized list of every Ingress in your cluster (vanilla, supported, unsupported, plus a separate tab for invalid/unknown annotations), with a per-annotation breakdown and the minimum Traefik version required to cover each one.
- A line-by-line translation of your ConfigMap into Traefik static configuration, entryPoints, middlewares, and access logs.
- A concrete scope, for the first time in the project. You can tell your team how many Ingresses are in the 99% versus the 1%. You can estimate the work. You can plan in sprints instead of quarters.
This is what I meant earlier when I said the hard part isn't doing the work. Migrating a vanilla or fully-supported Ingress is a kubectl command. Translating a direct-mapping ConfigMap key is a YAML change. The reason migrations feel impossible is not that the work is hard. It's that teams don't know, until they start, how much of the work is hard and how much isn't.
An audit tells you.
What Comes Next?
This is the first post in a series covering the full migration from Ingress NGINX to Traefik alongside our v3.7 GA. The next post will walk through installing Traefik with Helm next to your existing NGINX controller, in a configuration that serves the same Ingress resources in parallel so you can validate behavior without moving any traffic. The third will cover the progressive cutover: route by route, using IngressClass routing, L4 TLS pass-through, and a blue-green pattern that lets you roll back at any point with a single change.
For now, run the audit. You don't need v3.7 installed. You don't need to commit to a migration plan. You just need to know where you stand. Fifteen minutes from now, you will.
Resources
- Migration website: ingressnginxmigration.org
- Migration tool: github.com/traefik/ingress-nginx-migration
- Migration guide: doc.traefik.io/traefik/migrate/nginx-to-traefik (and the ConfigMap migration section)
- Annotation reference: Traefik NGINX Ingress Provider docs
- Community forum: community.traefik.io


