Do Machines Learn? Testing in Production with Traefik

Guest post by Alexander Dmitriev, Traefik Ambassador

Anyone who runs machine learning models in production while trying to improve model performance most likely knows about A/B tests. But what if you are the only machine learning engineer on the project? You must automate these tests as much as possible. And what if you have to make dozens of iterations per year and sometimes deploy new versions several times a week? Here is my story about the personalization of a large-scale book reading service and building the infrastructure to evaluate new models utilizing Traefik.
About MyBook
MyBook is a subscription reading service that publishes book apps for multiple platforms while striving to provide the best reading experience for our users. We've collected a huge catalog of books, audiobooks, ratings, and summaries that are conveniently always in your pocket. Bookmarks are synced across all our user’s devices and text-audiobook versions. Avid readers can use a subscription with unlimited reading, and those who want just one book can rent it for half price. My name is Alexander Dmitriev, and I am a machine learning engineer. My field of interest is personalization: recommender systems, user satisfaction measurement, and infrastructure for these systems. I love to solve problems end-to-end: discuss the user interface with the product manager, prepare data, train machine learning models, write the service, deploy to production, and support it.
Building a Smart(er) Recommendation Engine
Helping customers find books that are interesting to them is essential for a retail service like ours. MyBook already has talented editors curating popular book selections, so the next logical step was adding frequently updated personal recommendations. When I started at MyBook, my goal was to build a recommender system that discovered and suggested books that a customer might find interesting based on their behaviors. This service is known internally as recsys, and I'll be focusing on the evolution, automation, and maturation of that system in this post.
Production testing is critical for the development of machine learning systems like recsys. Simulating ephemeral properties such as serendipity, variety, and relevance is not feasible with more traditional approaches to testing such as unit or integration methodologies used during software development.
When the first version of the recommender service was ready, I added a Flask server, built a Docker container, and deployed it on a newly purchased cloud server. Backend engineers added NGINX as a reverse proxy with SSL support because it had been used for many years on our production systems. The recsys application Flask port was published to the host, and all requests were forwarded.
So, at first, the architecture looked like this:
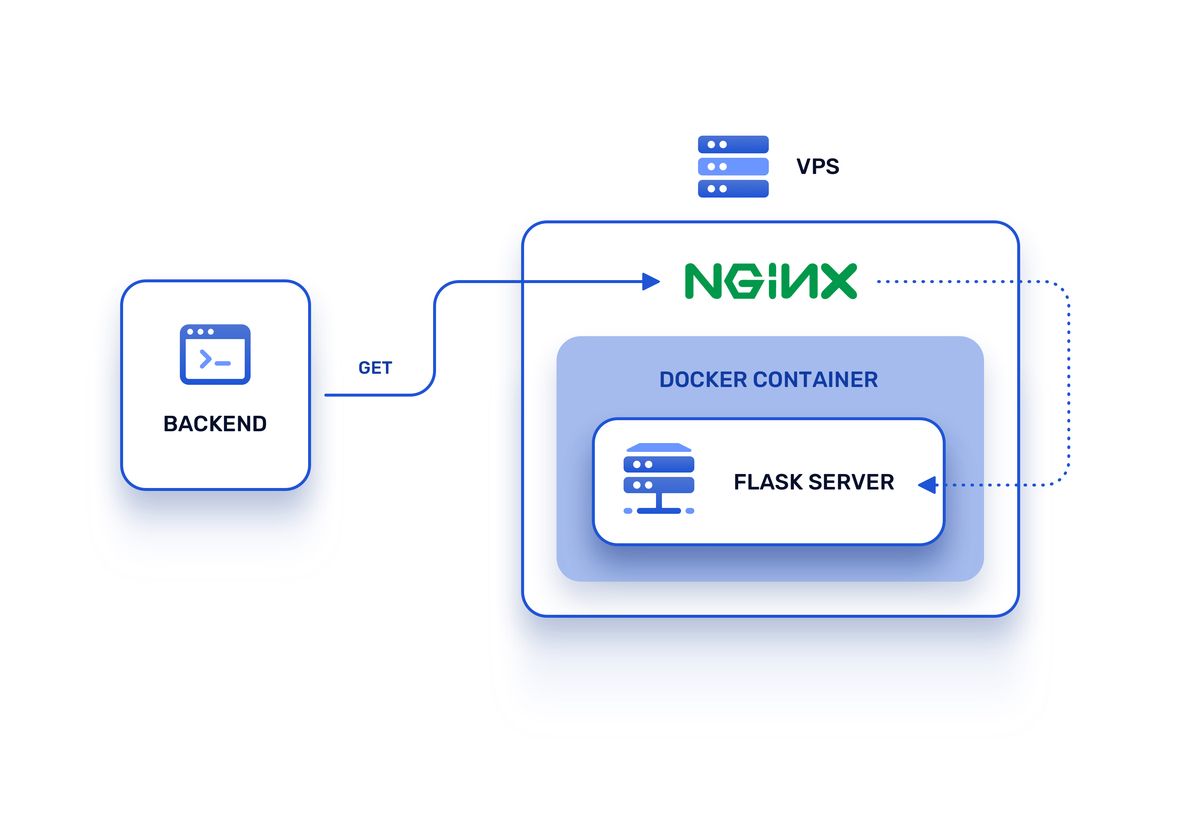
The Growing Pains of Productionized Testing
We regularly performed A/B tests where we measured the mean number of books our users added to their bookshelves during a single session. The end results showed us that personalized sets performed 30% better than a fixed set of bestsellers handpicked by our editors. Eventually, all new versions of recsys rolled out through the A/B test against the previous one in production. And it looked something like this:
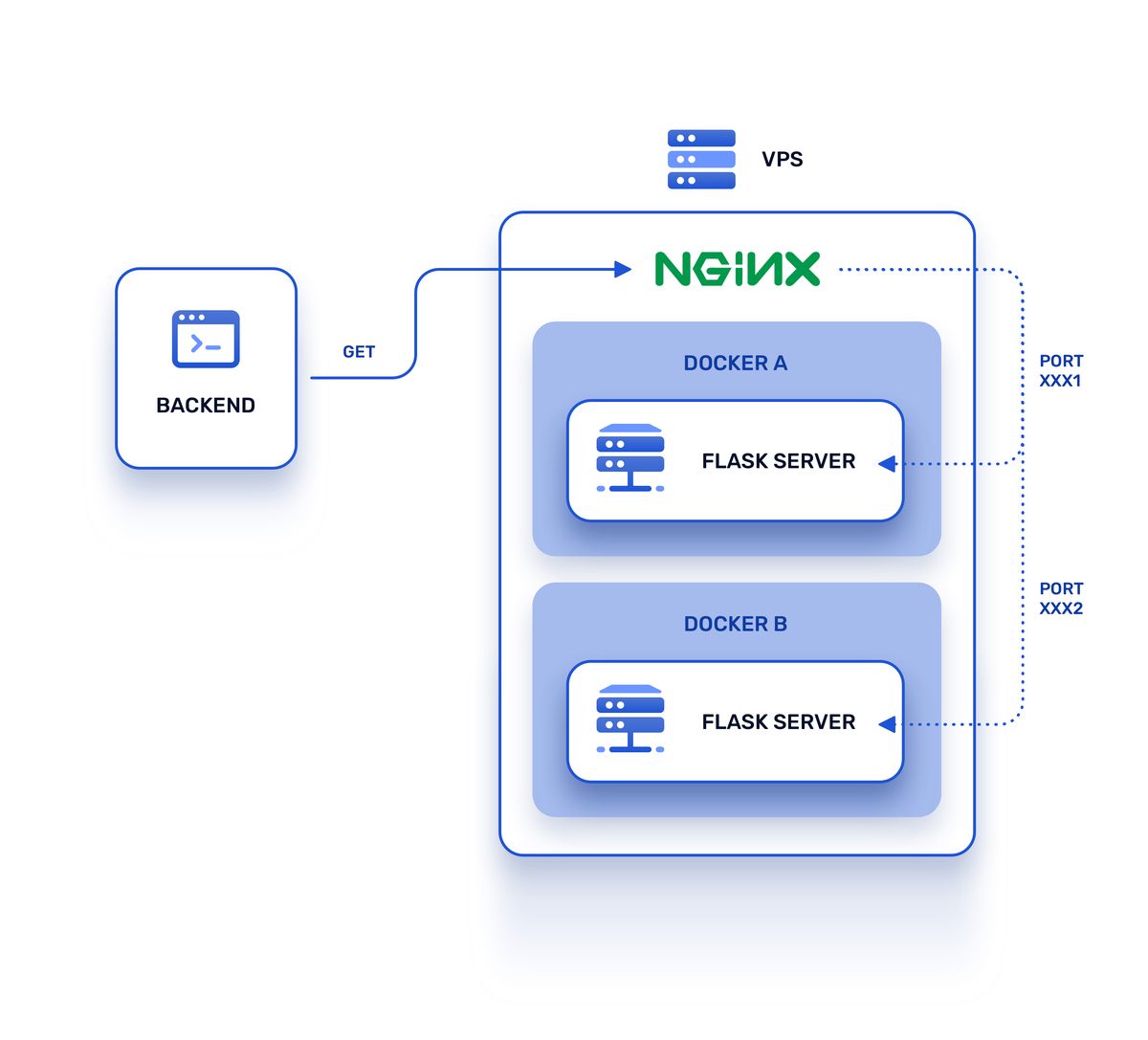
As time passed and new services appeared, the situation became messy and unmanageable:
- Many of the recsys services ports were hardcoded on the backend
- Prior to each A/B test the health checks, Prometheus exports, alerting rules, and Grafana dashboards had to be configured by hand
- This process was required any time a new version of recsys was deployed
As mentioned before, user tests are must-have in personalization tasks and it's crucial to be able to set up and teardown one as quickly and easily as possible, otherwise this overhead would have driven our velocity and impact close to zero.
Machine Learning at Scale
At this stage, it was clear that a better solution was required. I spent some time researching concepts such as service discovery, canary deployments, and cloud-native. Eventually, I discovered Traefik, a nice and easy to use reverse-proxy and load balancer which works natively with Docker containers and Docker Swarm.
After reading the Traefik documentation I discovered that I would get:
- auto-discovery of new containers
- health checks and routing only to healthy containers
- metrics endpoint for Prometheus
- configuration via Docker labels which means all my infrastructure will be described alongside my deployment manifests, perfect
- no more exposed ports on my containers, now they are secure and accessible only inside the Docker network
For a long time, I was curious about the the multi-armed bandit approach for recsys tests. The idea of this approach is to optimize some kind of reward (e.g. user satisfaction) during the constant test with adjustments made on the fly and to minimize resources (e.g. user sessions) used during the exploration of new choices (recsys models). It seems perfect if you want to test every small iteration or even several versions of service at the same time.
I ended up building a couple of different prototypes and came to this solution:
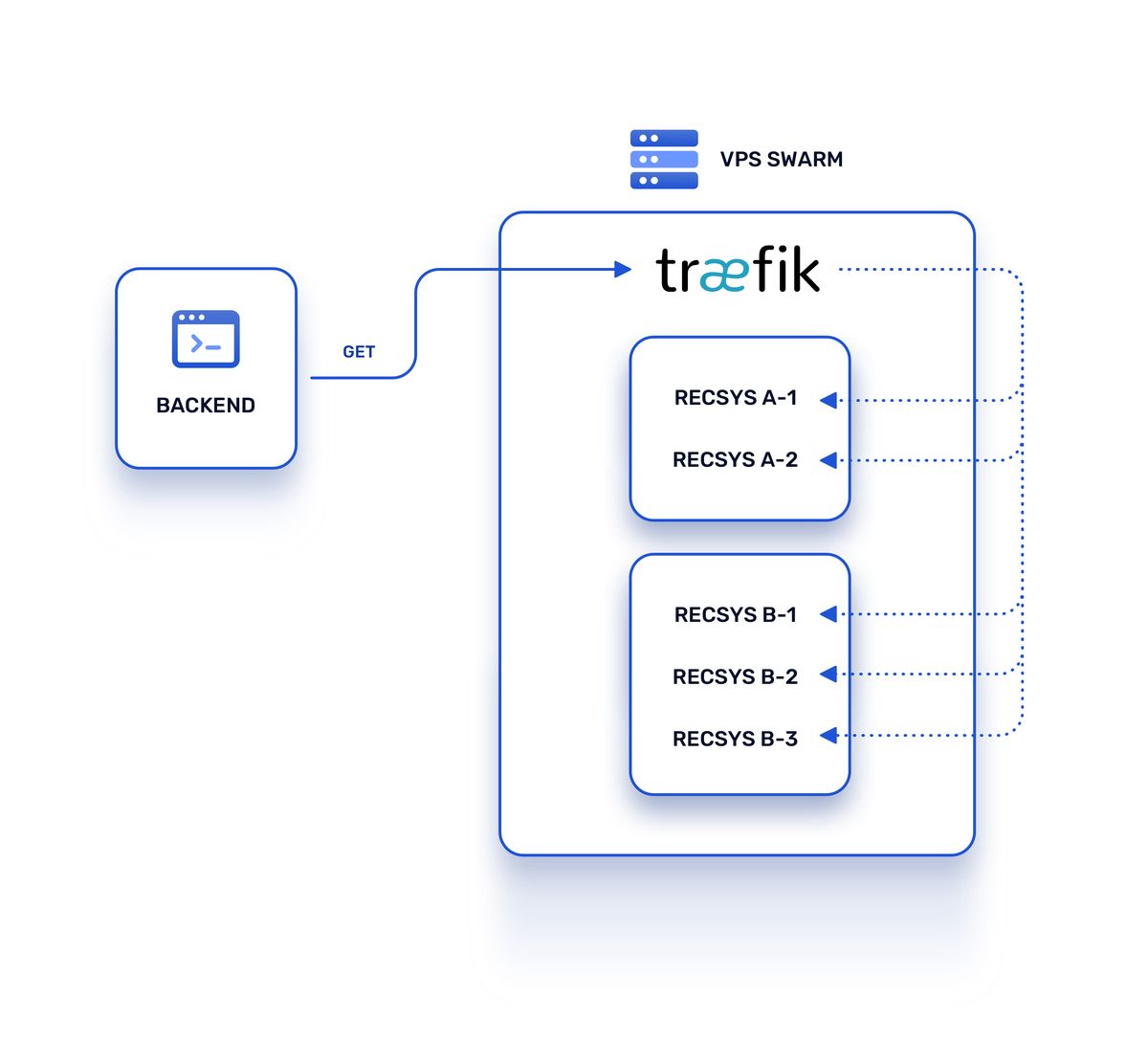
Every service became a router in Traefik terminology, and each recommender engine container became a service.
Traefik made it possible to assign multiple Docker services to one routing rule and split traffic between services while assigning weights to each one. So here is the most interesting part:
- The sum of all weights for different versions of the recsys would always equal 100
- All new versions were deployed with weight 1, so they received only 1% of user traffic
- Several times a day Python script recalculated recommender performance metrics for each version of recommender (for simplicity let's say CTR or click-through rate) and updated weights for models; so better performing ones receive more user requests while others receive less
Testing a new version of the recommender engine is as simple as adding a service definition to the docker-compose file and updating the stack. Docker Swarm finds the difference between the desired and current state, starts a new Docker container with `weight = 1`. Traefik finds this container and, after successful health checks, routes 1% of requests to the new version, all while exporting the metrics required for monitoring by our automated scripts. After a set amount of time the CTR metrics are recalculated and if users like the new version, it is reconfigured to receive a larger share of the traffic, and it is constantly being reevaluated against new models.
Traefik Helps Me Do What I Love Most
We are a small team and I am the only MLE on the project, so I insist on researching and utilizing tools that are easy to use and built with love for the end-user. Traefik definitely meets that criteria. Maintenance costs are close to zero, and the learning curve is flat. This approach is pretty universal no matter which container orchestrator you use and how you configure Traefik, whether you’re using Kubernetes, Docker labels, Consul, Etcd, or something else.
In summary, I’d recommend Traefik to anyone who needs reverse proxy with all necessary features such as service discovery, monitoring, and metrics exporting, which is easy to set up and maintain. It saved me a ton of time so that I could now spend fine-tuning algorithms and adding personal ranking to editors' handpicked book sets, which help users find the books they like. All this effort yielded book consumption increase by tens of percent.
Author's Bio
Alex Dmitriev is an engineer in embedded electronics and data scientist in metallurgy. Since 2018, he's been a machine learning engineer at MyBook, and is focused on personalization of user experience and infrastructure for ML services.


