Achieve Zero-Downtime Deployments with Traefik and Kubernetes


Rapid release cycles are the hallmark of modern software development. The cloud native ecosystem tooling includes containers, Kubernetes, microservices, and agile development methods, all of which support and encourage frequent delivery and deployment. The hidden downside, however, is that every change to production is another chance for something to go wrong.
In the worst-case scenario, that "something" means downtime.
Testing is always the first line of defense against service disruption. Unfortunately, cloud native application architectures can be surprisingly complex, and the full extent of the interactions between APIs and services can be hard to map and predict. Because of this, the traditional testing march from development through staging is unlikely to catch every issue before new code reaches production.
Today’s network-centric applications call for new, network-centric approaches to software testing and deployment. As a modern, cloud native edge router, Traefik Proxy is ready to help.
Routing around downtime
Containers and Kubernetes have revolutionized software delivery. Releasing apps and services as stateless container images makes it easy to create and destroy container instances as demand requires. Is an application experiencing a traffic spike? Operators may add additional instances to the cluster and use a load balancer to distribute requests accordingly.
This model gets really interesting, however, when instances of more than one version of the same software serve requests within the same cluster. Mixing old and new versions like this makes it possible to configure routing rules to test the production environment's latest version. More importantly, the new version can be released gradually – and even withdrawn, should problems arise – all with virtually no downtime.
Three popular deployment strategies to help you do so are blue-green deployments, canary releases, and A/B testing. Although all three are related, each is also distinct.
Blue-green deployments
In this pattern, “green” refers to the current, stable version of the software, while “blue” refers to an upcoming release that introduces new features and fixes. Instances of both versions operate simultaneously in the same production environment. Concurrently, a proxy router (such as Traefik Proxy) ensures that only requests sent to a private address can reach the blue instances.
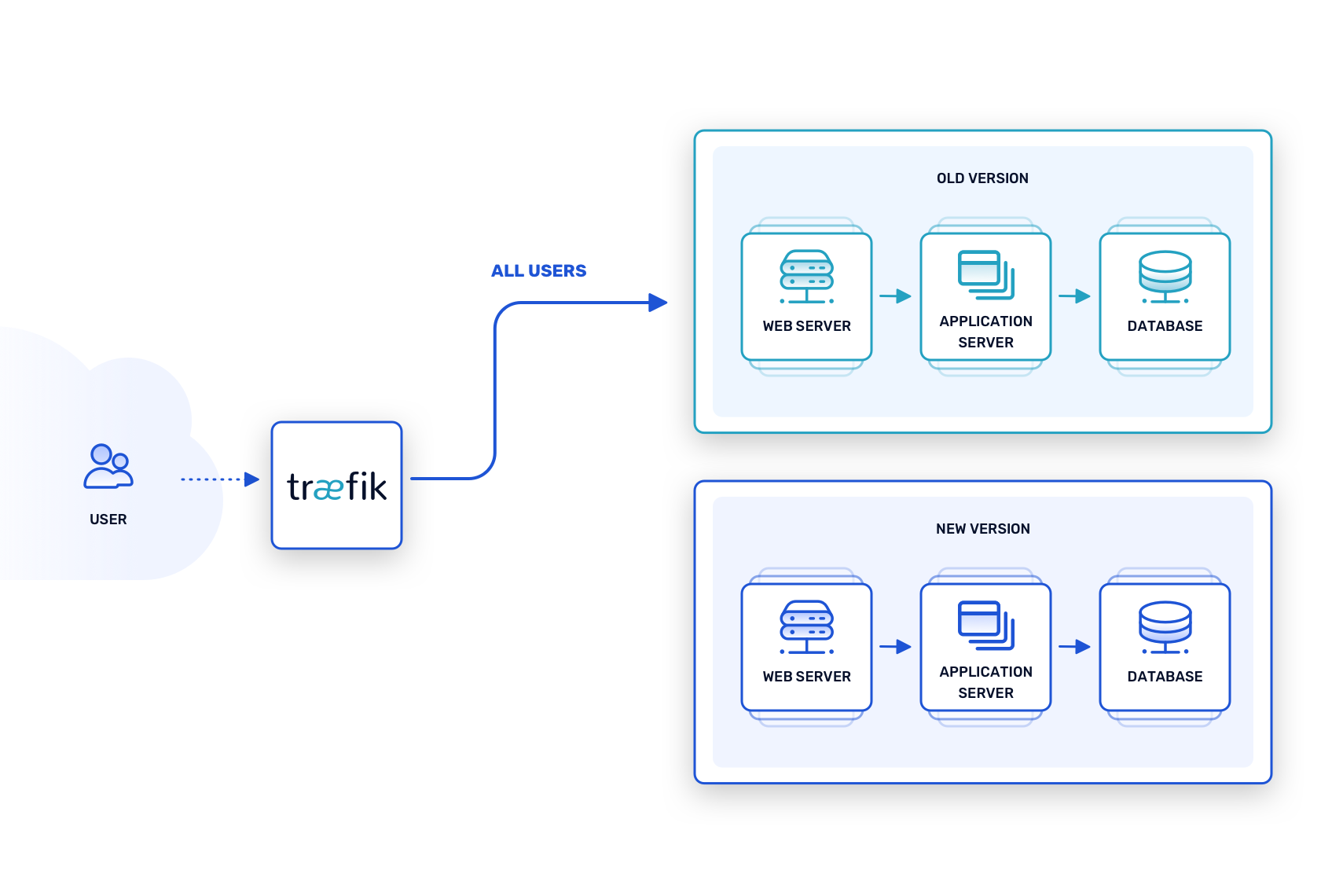
There are two ways to test such a setup. The first is to run synthetic tests against the blue instances, confident that they are being staged in an environment that matches production exactly. A more ambitious method involves traffic mirroring, in which the green instances handle incoming requests, but a duplicate of every request is also sent to the blue instances. Although this can be resource intensive, it creates an accurate simulation of what would happen if the blue instances were running the show.
Once all test cases and integrations are satisfied, switching over from the green to the blue version is as simple as updating the routing rules. In effect, blue becomes green, and eventually the next iteration of the software is deployed as the new blue. Equally important, it’s just as easy to revert the routing rules and roll back to the earlier green version, should some last-minute catastrophe occur.
Canary releases
The canary release model takes blue-green testing a step further by deploying new features and patches into active production, albeit in a measured way. The router is configured such that the current, stable version of the software handles most requests, but a limited percentage of requests route to instances of the new, “canary” version.
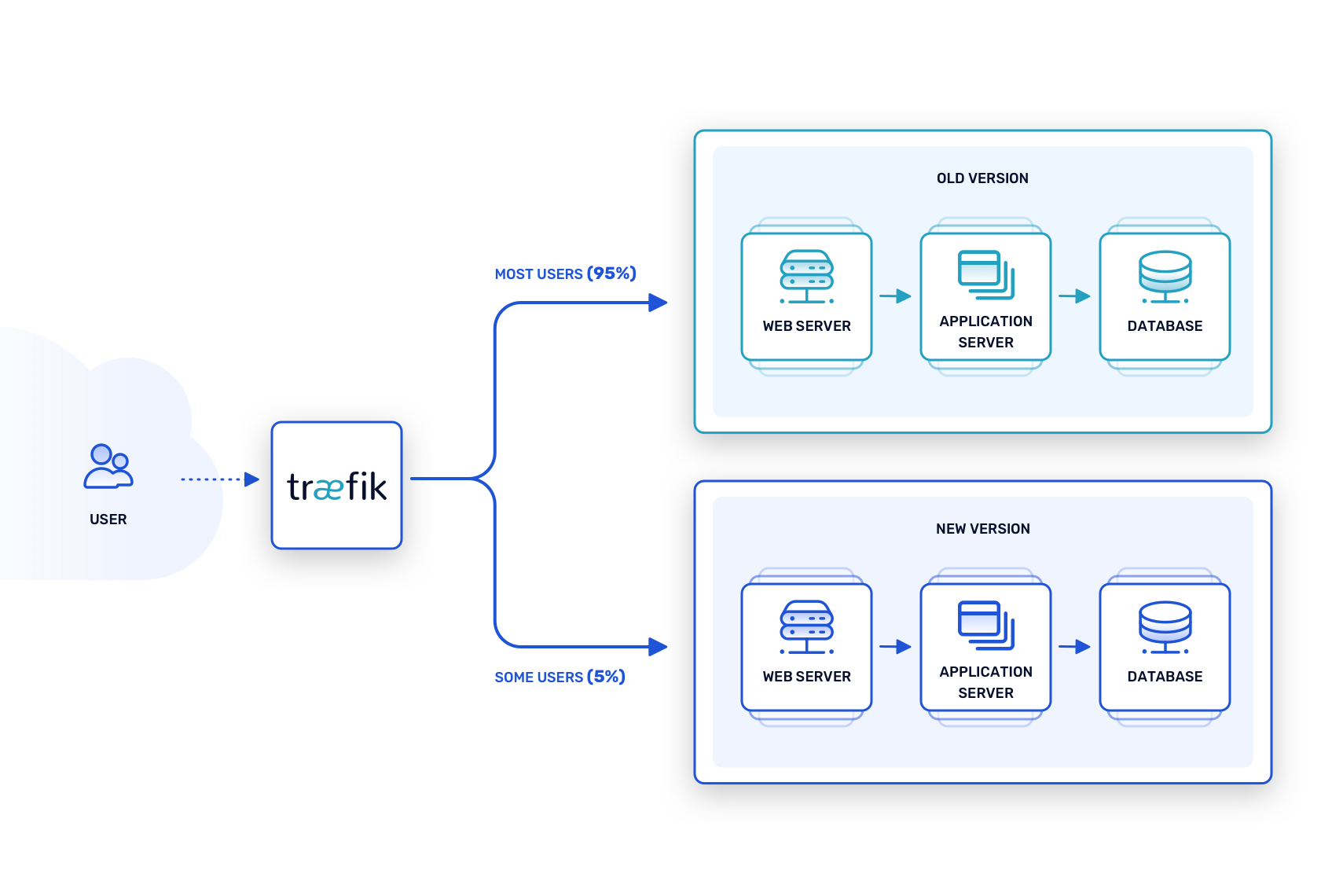
True to the “canary in a coal mine” metaphor, if instances of the canary release start dropping dead (or exhibiting problems in some way), they can be withdrawn for bug fixes while the stable release carries on as before. If things go smoothly, on the other hand, the proportion of requests handled by the canary release can be gradually increased until it reaches 100 percent.
This model breaks down quickly, however, when the canary release is too large and introduces too many changes at once. It works best for microservice architectures, where features or fixes can be released incrementally and evaluated on their particular merits.
A/B testing
This technique is sometimes confused with the previous two, but it has its own purpose, which is to evaluate two distinct versions of an upcoming release to see which will be more successful. This tactic is common for UI development. For example, suppose a new feature will soon roll out to an application, but it’s unclear how best to expose it to users. To find out, two versions of the UI including the the feature, run in tandem – Version A and Version B – and the proxy router sends a limited number of requests to each one.
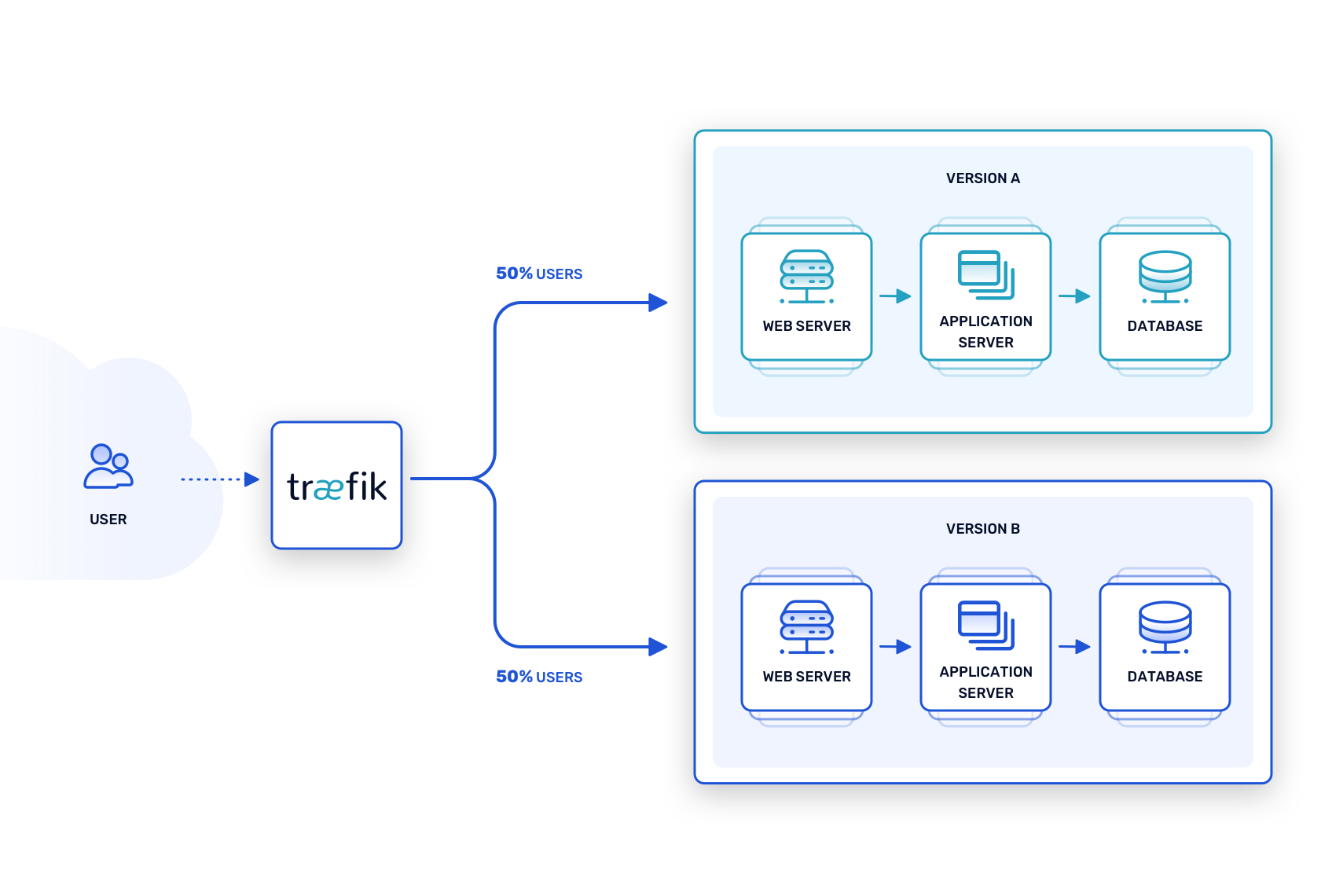
From there, metrics can help determine which version is the better choice. Does Version A do a better job of convincing users to try the new feature? Do users complete the UI sequence faster using Version B, or do they tend to cancel before the end? Each version of the new UI can be trialed with a small number of users while routing rules ensure that the stable version continues to serve the majority of requests.
Network effects
These techniques can be invaluable for testing modern, cloud-native software architectures, especially when compared to traditional waterfall-style deployment models. When used correctly, they can help spot unforeseen regressions, integration failures, performance bottlenecks, and usability issues within the production environment, but before new code graduates to a stable, production release.
What all three approaches share in common is that they rely on the ease of deployment afforded by containers and Kubernetes, coupled with cloud-native networking techniques, to route requests to testable deployments while minimizing disruptions to production code. That’s a powerful combination – one that’s squarely within Traefik’s wheelhouse – and if employed judiciously, it can effectively bring overall application downtime to zero.
Looking to understand the critical role that networking plays in modern application deployments with Kubernetes? Look no further than our recent white paper on Kubernetes for Cloud-Native Application Networks.








