Kubernetes Clusters as a Service Using the GitOps Approach


At Traefik Labs, we really love automation. We should not have to work for the computers; the computers should work for us.
Docker and Kubernetes have helped us reliably manage workloads and services in diverse environments, but to do so efficiently and at scale, we need to automate the management of Docker and Kubernetes clusters. In particular, we need to automate the self-healing, autoscaling, and observability of our clusters. We also need a common base where we can add the security and observability standards that we want on all our clusters. Finally, the processes for automation must be easy and intuitive for our developers to follow.
Our previous deployment strategy for provisioning clusters and deploying manifests was fragmented and involved manual intervention in a few places. As a result, it cost engineers time and made the process of scaling the platform longer.
Nowadays, we have tools that allow us to manage platforms like we manage software components. We tried and successfully switched our platform tooling to a GitOps approach with the help of Flux and Cluster API.
Our goals
There were a few non-negotiable goals for our new approach to automation using GitOps:
- A fully auditable and observable state across all our clusters
- The ability to easily create clusters on demand, with no need to manually configure in terraform, argocd, github etc.
- No need to manage individual nodes
- Autonomy for our developers
- Autoscaling and self-healing capabilities
- A more familiar approach to deploying clusters, with custom Kubernetes manifests
- Processes for peer review on all changes
Global architecture
The global idea of GitOps is to have one single repository through which you can manage all your clusters. This Git repository is your single source of truth that enforces the desired state for all clusters in your architecture.
In our main repository, we want to deploy and configure our clusters according to our needs. We also want to deploy base resources, like an observability stack or multi-env software.
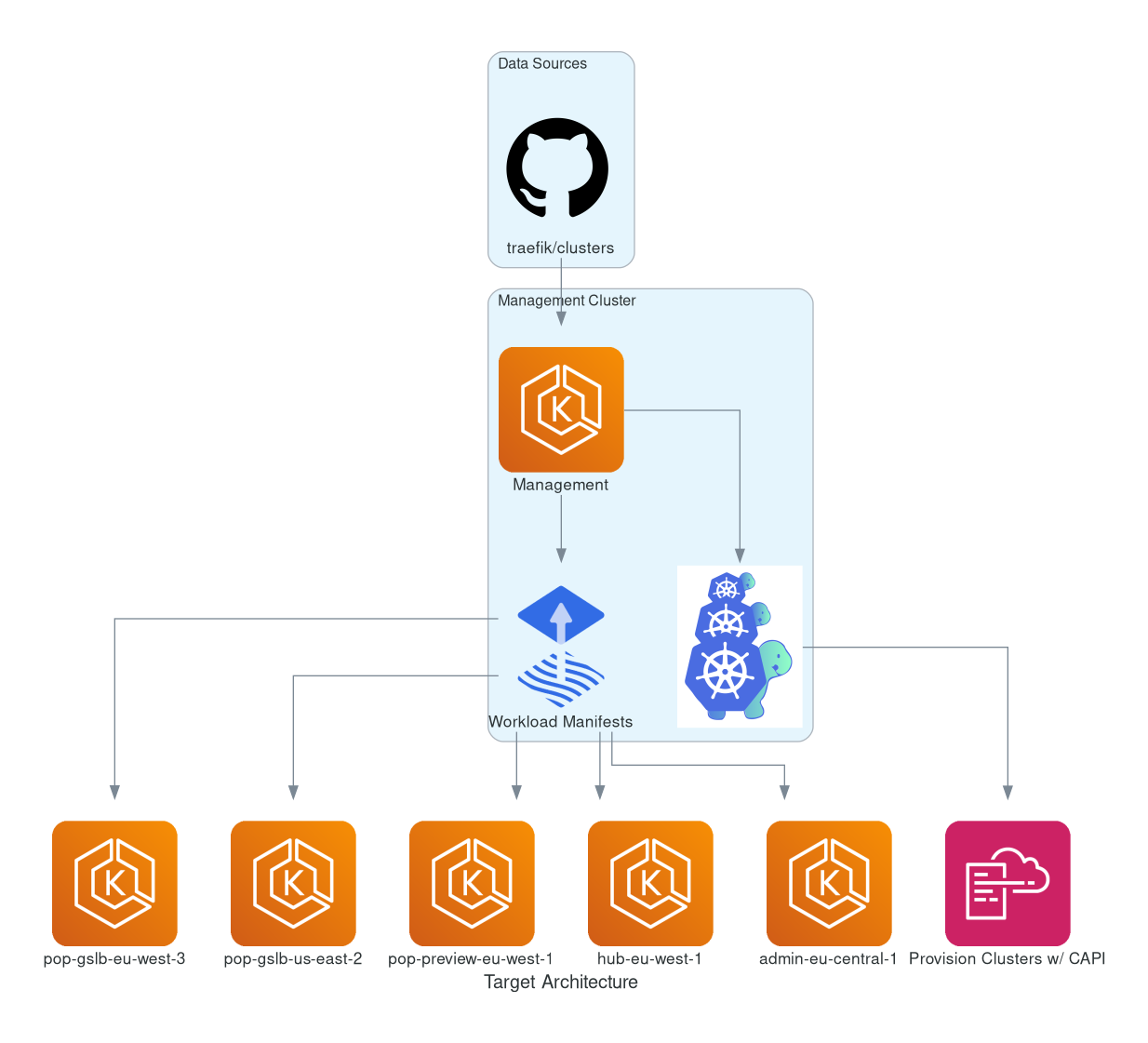
With Flux and Kustomize, we can override those base resources in an overlay, for instance, to override requests and limits of a deployment for the production environment.
What is Flux?
Flux is a tool created by Weaveworks, the inventor of GitOps. It enables deployment (CD) through automatic reconciliation on a Git repository. It works with YAML files and Kustomize. You can apply some variable substitution, use SOPS integration and even use Helm if you need to. It integrates well with Prometheus and Grafana.
What is Cluster API?
The Cluster API (a.k.a CAPI) allows you to create and manage your clusters declaratively in YAML files as you are used to with your application workloads.
Instead of Pod, Deployment, or Service, we declare Cluster, MachineDeployment, or MachineHealthCheck in its YAML files, using CRDs provided by this SIG of Kubernetes.
It works with many providers and you can use it on bare metal servers or with a cloud provider.
Directory layout
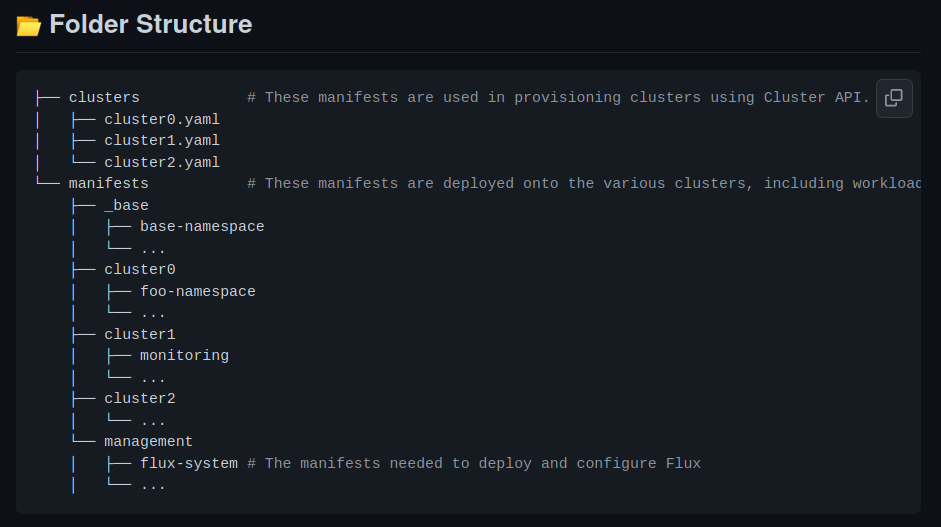
Note: You can try a (local) demo of this setup on this public repository by one of our Platform Engineers.
We use Traefik Enterprise as our ingress controller for all clusters. It comes with all features of Traefik Proxy, and it’s way more convenient for production environments. All Traefik Proxy features are distributed, including an API Portal, Service Mesh, Hashicorp Vault support, and OpenID Connect middleware. In a production environment, the cluster-wide dashboard is quite handy for understanding a specific situation on your dynamic configuration with your ingress controller.
Even if our Let’s Encrypt integration is production-ready, we chose to use cert-manager to handle our certificates like all the other resources; as a regular Kubernetes object.
We include our full-fledge setup in the base tree:
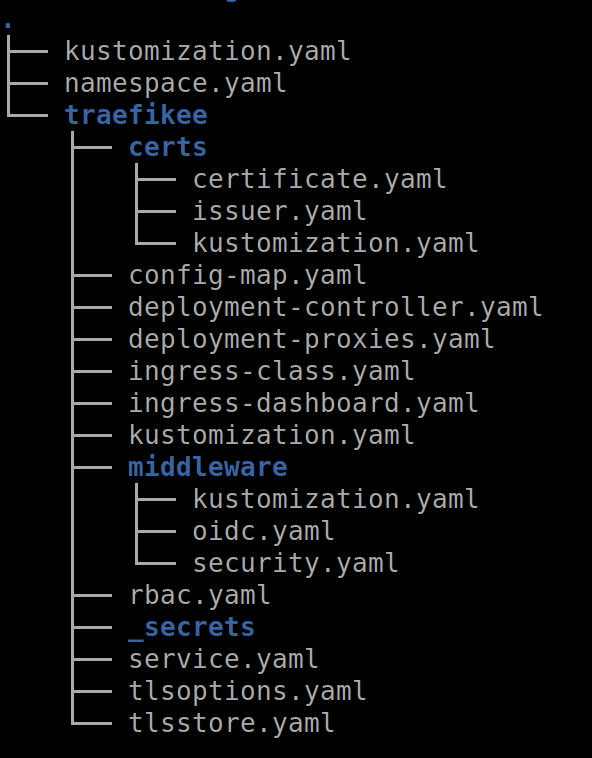
Afterward, we may apply some Kustomization in a cluster overlay.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: proxy
namespace: traefikee
spec:
template:
spec:
containers:
- name: proxy
resources:
requests:
memory: 600Mi
cpu: 600m
limits:
How do you manage external resources like CDN, DNS, or storage?
For now, we're still using Terraform. We’ve not (yet) finished our journey on those kinds of resources.
With a Data Source, we get an (automatic) DNS name for load balancers created with Cluster API and add a business-friendly CNAME record pointing to it. It’s the same when creating object storage for backup or other specific infrastructure needs.
Our ultimate goal is to be able to provision all our infrastructure with a GitOps approach, using simple declarative files and the reconciliation engine.
So, we are looking for and testing alternatives like external-dns, Terraform Operator from Hashicorp, and Crossplane and their Flux Terraform Controller.
On the storage side, there are now many ready-to-use and production-ready CSI drivers.
How can this architecture scale automatically?
Well, there is a ClusterAPI provider for cluster-autoscaler.
It can work in a secure way, where the credentials are not stored on workload clusters. Autoscaler can manage the workload cluster from the management cluster, like Cluster API:
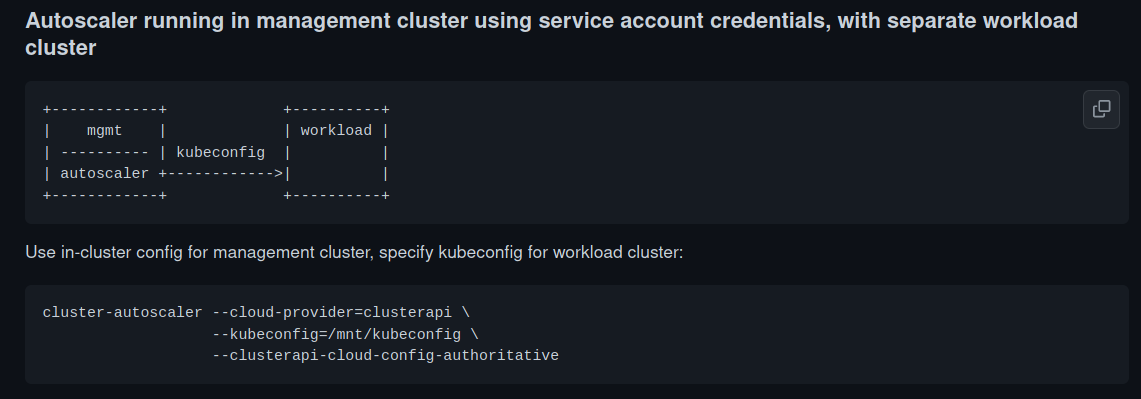
Note: There is currently an issue with kubeconfig. Cluster API refreshes it very often, and cluster-autoscaler does not use the renewed kubeconfig. So we submitted an issue upstream, and we managed to work around it with a reloader on cluster-autoscaler deployment.
What happens if a node has a problem?
With ClusterAPI, you can use MachineHealthCheck to define the conditions when a node should be considered unhealthy.
The MachineHealthCheck will initiate remediation on this node, by deleting the corresponding machine. Cluster API will then ask a new machine to your infrastructure provider.
How can developers be autonomous?
Our developers work on their own Git repositories.
They have two major needs:
- Capacity to let the product/QA team test their code automatically on a preview/staging environment
- Capacity to push a validated version of their software to the production environment, and revert easily if needed
For the first deployment, we handle the creation of all the needed Kubernetes resources and secrets. When we are ready, we review this deployment with (at least) one of the developers.
Afterward, using Flux we configure an ImagePolicy to watch on the Docker repository and update a deployment according to this policy. This ImagePolicy will commit this update to our single source of truth: our Git repository.
So, we changed the CI to publish the last version of the Git repository on the Docker repository, and we made two policies:
- An ImagePolicy to apply the last uploaded Docker version to the staging environment
- An ImagePolicy to apply the last SemVer tagged version to the production environment
In both cases, all changes are auditable: we can see those changes in the commit history of our Git repository.
What about when an error is committed to the (infra) Git repo?
Firstly, this does not happen often because every change has to pass CI checks. With this level of automation, you can pass a significant amount of your time on your CI to apply linters and schema validation on all your changes.
Secondly, with an overlay, you can validate a change on a staging/preview cluster before applying it to all clusters.
But yes, despite all this, it is still possible for an error to be committed to the Git repo. And when it happens, we have two options:
- Suspend (temporarily) Flux Kustomization, with Flux CLI
- Revert the commit in Git
Note: You can use those options at the same time.
We also protect ourselves with a velero backup of the management cluster. For disaster situations — for instance, if there is a blackout in a region of our cloud provider — we are able to restore a management cluster and reconnect or restore our workload clusters.
And how do you manage the same kind of cluster deployed multiple times?
In this case, you don’t want to copy-paste source code. It will be error-prone, and you won’t be able to handle changes efficiently on those clusters.
At first, we did use a code generator, like jinja2 or jsonnet. It works, but it can quickly become overwhelming with all the files generated. Each time you add a new cluster, the pull request will modify more and more files.
We’ve experimented with a simpler approach: use Flux with a local Helm template containing all Cluster API-related objects.
It’s quite straightforward, and since the chart is on our Git repository, we can manage it completely. We won’t be blocked because we need this specific configuration option which is not available in the official upstream helm chart.

After creating a template, we can use a Helm release configured to use a chart in a Git repository. This way, complexity coming from code generation is avoided, and the pull request contains only the change to review.
How do you stay up to date?
We want to manage the lifecycle of all our dependencies like all the other changes: with a pull request. Since we’re using many open source components, we can use Renovate.
When upstream publishes a new version on their Docker Repository, Renovate opens for us a pull request. We can then review it and improve it if this version needs specific changes on our side.
It’s quite versatile and can even include the changelog inside the pull request if it comes from a GitHub release or a changelog.md. It’s really easy to stay up to date with this kind of tool.
Conclusion
In this post, we shared how we managed to attain our goals on platforms with a combination of Flux with the Cluster API to enable GitOps for cluster creation and management. This gave us all of the benefits of GitOps during cluster and platform creation.
Without CI/CD pipelines, our deployments are straightforward to understand. Developers can see their software in production without having to understand all the mechanics behind the deployment in production.
Even without deep knowledge of infrastructure, they have access to and can read the YAML files we built together to deploy their software in production. This is far easier to understand than working with Puppet, Salt, or even Ansible.
We have not finished our journey to move all of our infrastructure to GitOps, but we have already seen the benefits of it. With those kinds of tools, we are clearly more efficient in managing platforms.


