Beyond the Models: Operationalizing Enterprise AI


Today’s AI landscape moves at a breakneck speed. Hugging Face alone now hosts nearly two million AI models—hundreds of thousands added each month, exemplifying the astounding pace of innovation. While remarkable, this proliferation creates an often-overlooked challenge: the true difficulty in enterprise AI isn't picking the perfect model; it’s building a flexible, scalable architecture around it.
The Real Challenge: Operationalizing AI
Choosing a model (e.g., GPT-4, Claude, Grok, or Llama) is just the start. The deeper, more pressing issue for enterprises is operationalizing these models effectively. Organizations must navigate complex decisions:
- Model Selection: Should your organization use open-source models for flexibility, proprietary models for advanced capabilities, or custom-trained models tailored to specialized applications?
- Deployment Environment: Is the public cloud the right choice for its scalability, or does your enterprise require the enhanced security of a private cloud? Or maybe the best option is a carefully managed hybrid solution.
- Implementation Approach: Will your teams benefit more from assembling best-of-breed components internally, choosing vendor-provided turnkey solutions for rapid deployment, or adopting a balanced hybrid approach?
Most enterprises land somewhere in between—heterogeneous environments are the norm, not the exception. Successfully managing this complexity becomes the defining factor for scalable AI operations.

No AI Without APIs. And No APIs Without API Management.
AI endpoints and APIs are deeply intertwined. APIs have become the lifeblood of agentic AI systems, acting as secure bridges for agent workflows, enabling dynamic endpoints for tools, data access, and maximizing operational efficiency. This explosion of APIs necessitates robust API management, turning APIs into the vital control plane for your entire AI infrastructure. They manage secure access, enforce governance, and facilitate dynamic behavior, which is crucial for agentic AI workflows.
APIs also enable enterprises to implement consistent policy enforcement, streamlined developer experience, and comprehensive audit capabilities across their entire AI ecosystem. The rise of agentic AI further underscores the importance of APIs as essential bridges connecting diverse models and applications securely and efficiently.
Avoiding the Biggest Anti-Pattern in AI Architecture
One common yet detrimental practice is embedding API runtime capabilities directly within the model runtime environment. This creates substantial problems that limit scalability and agility:
- Vendor Lock-in: Ties your organization to specific model providers, reducing flexibility and increasing costs.
- Limited Enterprise Capabilities: Embedded APIs frequently lack advanced features needed for large-scale, mission-critical operations.
- Non-Standard Compliance: Frequently breaks compatibility with widely accepted standards, such as OpenAI’s API specifications, complicating integration and maintenance.
You might already face these issues if:
- Your organization struggles to integrate API token generation seamlessly with existing identity management systems.
- You lack standardized, vendor-neutral observability tools for effective monitoring.
- Your AI endpoints aren't easily shareable through centralized developer portals.
Recognizing and addressing these indicators early can significantly enhance your ability to scale AI responsibly.
Strategic Decoupling Through AI Gateways
A superior architectural choice involves strategically decoupling your model runtime from your API runtime, connecting them via an AI gateway such as Traefik Hub. Here’s why it matters:
1. Future-Proof Flexibility
Models constantly evolve. Decoupling ensures seamless integration of new models, allowing your enterprise to adopt emerging technologies quickly without disrupting existing operations.
2. Centralized, Scalable Security
Manage authentication, authorization, and access control across diverse models centrally, maintaining consistent, enterprise-grade security and guardrail policies regardless of which model your applications consume.
3. Infrastructure and Policy-as-Code
Use Kubernetes-native, cloud-native, and infrastructure-as-code (IaC) approaches to automate deployments, significantly reducing operational overhead. Implement and enforce policy standards like semantic caching, guardrails, and content filtering in a structured and version-controlled manner.
4. Vendor-Neutral Observability
Leverage OpenTelemetry to achieve consistent, vendor-neutral monitoring of metrics, logs, and traces across your entire infrastructure, ensuring deep visibility and efficient troubleshooting capabilities.
Practical Deployment Scenarios
Let’s look at how strategic decoupling works practically:
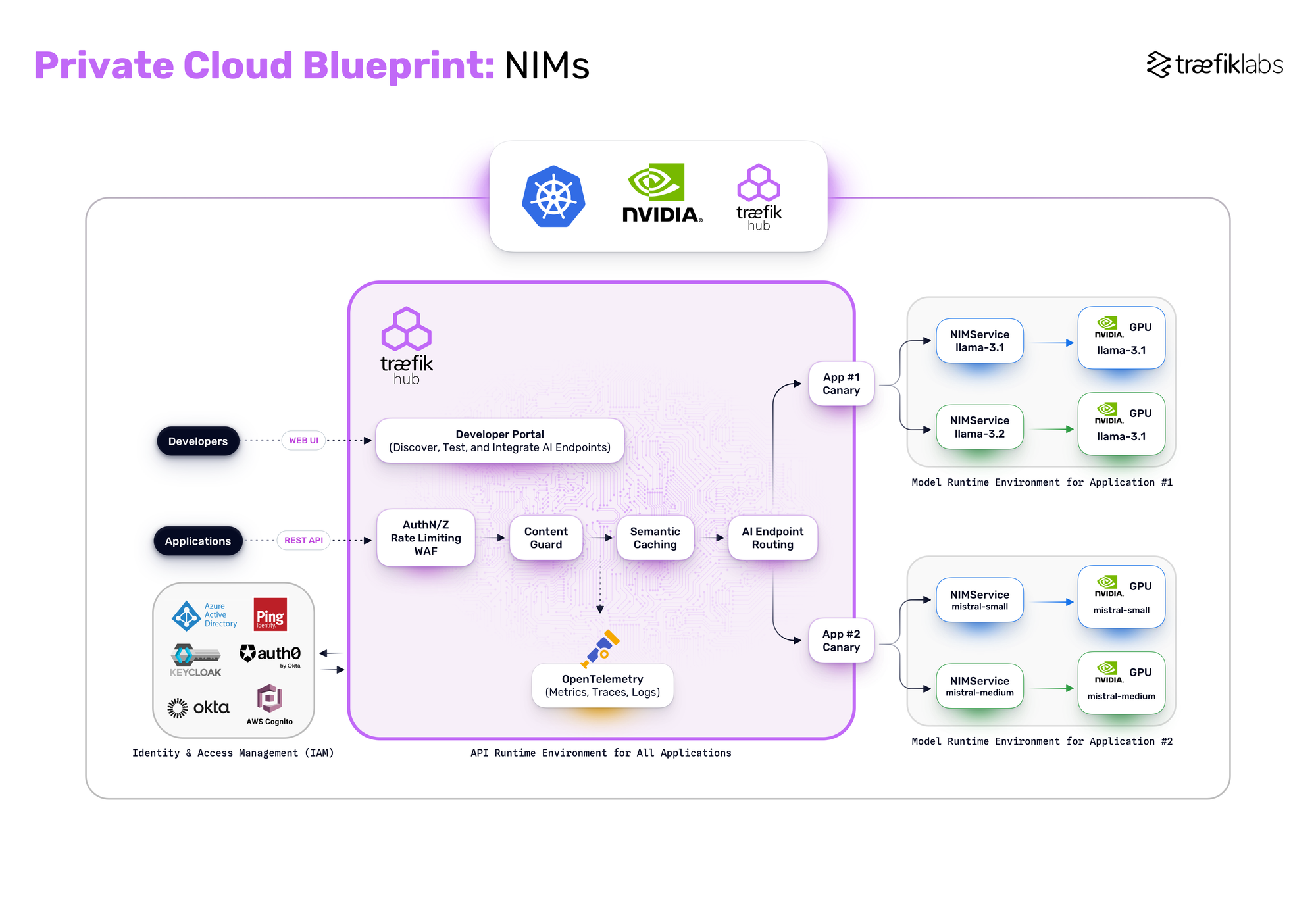
Private Cloud with Containerized Models
Deploy GPU-accelerated, containerized models using platforms like NVIDIA NIMs or KServe:
- Centralized API gateways handle developer portals, JWT authentication, rate limiting, and PII masking.
- Semantic caching via Redis, Milvus, or Weaviate improves efficiency and cost management.
- Advanced routing and canary deployments enable the safe and dynamic introduction of new models, reducing risk and accelerating innovation.
- Observability metrics allow for custom scaling flows based on AI specific metrics like token count, latency per model, and more.
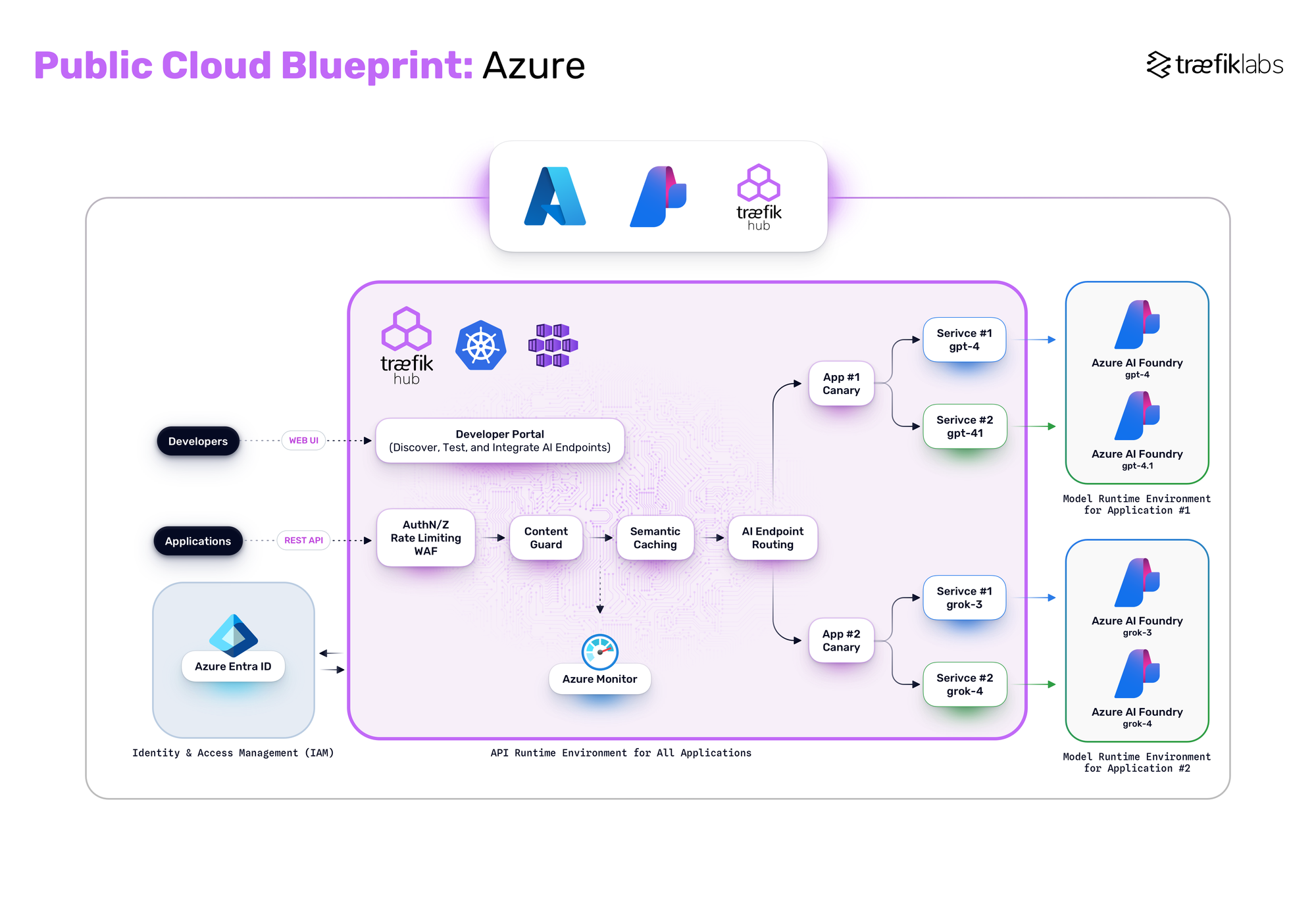
Public Cloud Managed Services
Using managed services like AWS Bedrock, Azure AI Foundry, Google Vertex AI, or OCI GenAI:
- Standardize API interactions via AI gateways integrated with OpenAI-compatible proxies.
- Maintain governance through centralized policy controls and cloud identity providers.
- Enable model switching and updates without any client-side disruptions.
- Provide unified developer experiences across different managed services.
Scaling Responsibly: Guardrails and Cost Efficiency
To scale AI responsibly and economically, you’ll need the following capabilities:
- Content Guardrails: Use gateways to enforce responsible AI practices by masking, blocking, or simply flagging sensitive data, inappropriate data, or off-topic content.
- Semantic Caching: Implement semantic caching to reduce redundant inferencing, significantly cutting costs and enhancing performance.
- Dynamic Routing and Experimentation: Avoid hard-coding models to applications; dynamically route traffic to test and optimize model performance seamlessly, ensuring flexibility and robustness.
Start Small, Build for Scale
Enterprises often face complexity paralysis. The solution is incremental yet strategic:
- Begin with an AI Gateway: Establish this crucial decoupling foundation to enable flexibility from the outset.
- Incorporate API Management: Layer in robust governance, comprehensive observability, and efficient developer experience.
- Progressively Add Policies: Gradually expand with semantic caching, content filters, and detailed usage policies to enhance security and efficiency.
- Prepare for Agentic AI: Build readiness for autonomous workflows and multi-model dynamic interactions, positioning your enterprise as a leader in next-generation AI.
The Bottom Line
True scalability in enterprise AI isn’t about betting on today's "best" model—it’s about building an adaptable, resilient architecture. By decoupling runtimes, implementing robust API management, and adhering to open standards, enterprises can confidently face the challenges that lie ahead in AI advancements.
Remember: Models are commodities. Architecture is your strategic advantage. Build wisely, and you’ll not just scale AI, you'll scale your enterprise's agentic future.


