


What is Service Discovery and How Is It Applied in Microservice Architectures?
Microservice architectures have enabled organizations to deploy software at accelerated speeds. By splitting applications into small pieces called services, they allow software releases to be deployed frequently and at scale. Due to their many benefits, microservice architectures have grown rapidly in adoption over the past few years and have become the gold standard for information technology.
While chock full of benefits, microservice architectures can nonetheless be complex to manage as they consist of so many components. To function effectively, all services must be able to locate and communicate with one another, between the client and the application’s back end. This is not always easy in microservice architectures, and it becomes ever more difficult as an architecture scales. This is where service discovery comes into play.
What is service discovery?
Service discovery is the process of automatically detecting services on a network. It solves the problem of how you connect the applications in your network. Without service discovery, developers have to manually input the addresses a client app requires to send requests to another app or server. This means they have to maintain a long list of static addresses, which is feasible for small projects but impractical in large environments. Service discovery automates this process and stores addresses dynamically in a service registry, so services can locate and communicate with one another more easily.
As a method, service discovery brings together the application, the client, and the service registry to store and maintain network addresses of individual microservices. If you are wondering how it works, microservice instances may register themselves with the service registry and provide their locations, or they could be automatically discovered by the service registry. At any time, clients can access the service registry to find the exact address of a given service.
There are two types of service discovery: server-side and client-side. You either do it directly in your application, or you use the diverse solutions on the service-side. Let’s explore each in detail.
Client-side vs. server-side service discovery
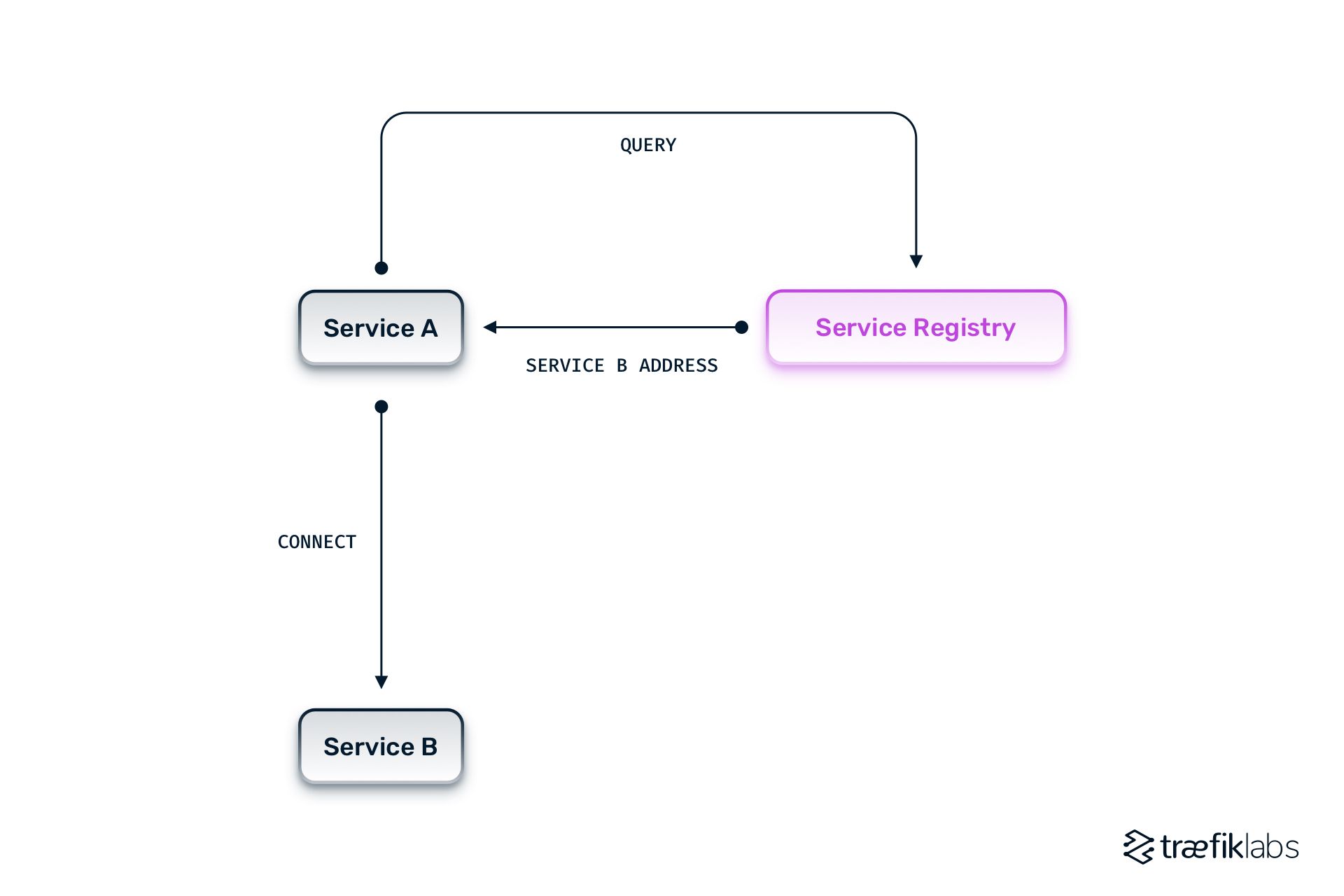
What is client-side service discovery?
Client-side discovery allows client applications to discover services by directly viewing or querying the service registry, which stores service instances and endpoints. The client and the service registry are coupled and are essentially one and the same. The entirety of service discovery is handled on the client side of the application. You input the inspected address and then watch it be connected to the application.
This approach has some advantages, namely that it is relatively straightforward to understand and implement. The biggest drawback is that you have to maintain the complexity of the code in your application. This defeats the main purpose of running microservice architectures, which is to break down application logic to the smallest pieces required while removing responsibilities that can be addressed for every piece at a higher layer, in this case, service discovery capabilities.
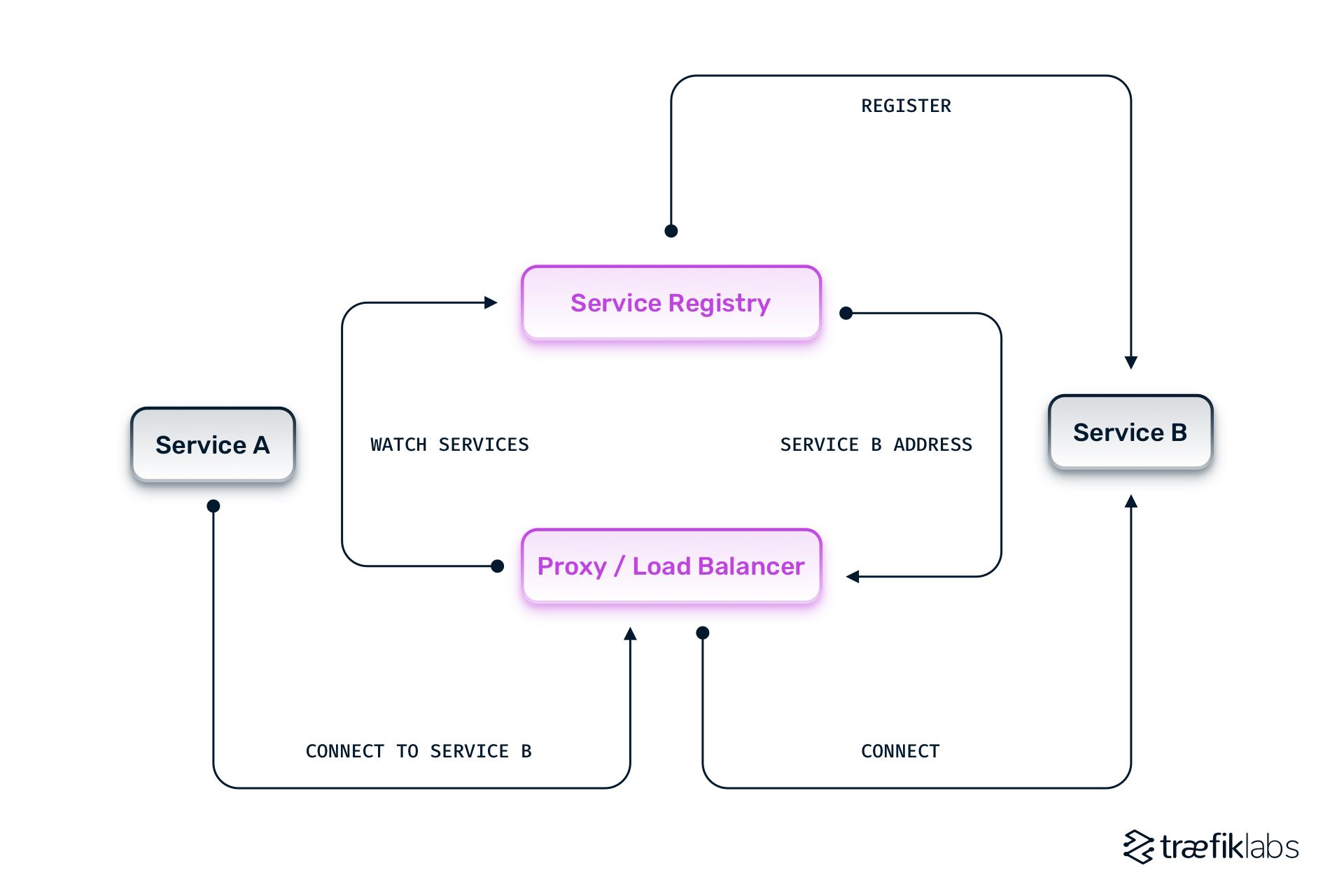
What is server-side service discovery?
This approach to service discovery decouples the client and the services registry. The client side of the application uses a proxy or load balancer, such as Traefik Proxy, that communicates with the service registry to identify the location of services. The service registry provides the application with the alias hostname or DNS address of the correct service, and it contains all the logic of storing an updated list of addresses. The load balancer can then route the request from the client to the correct service.
What is a service registry?
The service registry is a database that stores the network locations of all available microservices. As such, it needs to be highly available and updated continuously. Strong mechanisms are required to make sure the data is accurate in the service registry. There are different ways services can be registered in the service registry — self-registration and third-party registration.
What is self-registration?
In self-registration, the microservices register themselves and their addresses in the service registry. They communicate with the service registry on an ongoing basis to ensure their registry does not expire. An example of this would include using the Consul Catalog as the service registry. The application registers itself in Consul Catalog, and other applications can then query Consul Catalog with the name and connect it to the back end of the application.
What is third-party registration?
In third-party registration, the microservices do not register themselves in the service registry. In fact, there is no requirement for any change in the application itself. Instead, something else must run parallel to the application. To be specific, a sidecar proxy is run beside your app and handles the service discovery for you. It transmits the location of microservices to the service registry and connects the network to the proxy. Most service mesh platforms leverage the sidecar approach, except for Traefik Mesh which uses the host/node DNS approach. The sidecar approach carries several disadvantages, namely that they increase the operational complexity of an architecture.
Service discovery with Traefik Proxy
Traefik Proxy enables developers to implement server-side registry at scale, as it is an open source reverse proxy and load balancer that includes automatic service discovery. Traefik Proxy is a flexible solution that integrates with both the Docker and Kubernetes providers. It also allows developers to customize how the application is exposed, usually just by adding a label or an operation that Traefik Proxy can use to do complex and customized routing configurations. It means you don’t have to run a sidecar proxy, or modify your application directly making for a simpler architecture with straightforward service discovery.
Service discovery means developers can spend less time mapping infrastructure environments and experience fewer headaches in the process. They can reproduce environments without constantly changing the configuration, as the addresses are automatically stored and updated in the service registry. Whether you opt for client-side or server-side service discovery, know that your choice will enable you to scale the size of your microservice architecture while increasing its speed and efficiency.