Understanding Networking Complexity and Why Traefik Hub Is The Pain Relief You Need


In case you missed the big news a couple of months back, Traefik Hub, our newest product, is now in GA! Traefik Hub is a cloud native networking platform that helps you publish your containers at the edge instantly and securely.
If you have no idea what I’m talking about, fear not! In this article, I will introduce you to service publishing, what it actually is, why it's complex, and how Traefik Hub streamlines the process.
But before we jump into the wonders of Traefik Hub, let’s start with the basics.
A super-quick networking 101
In order to fully understand Traefik Hub and why it's so powerful and awesome, we need to revisit networking fundamentals.
Gather your tools
Service publishing refers to the process of making your service accessible to internal and external third parties (in addition to the developer). To do this, you need some basic networking components. Depending on the type of network you are building, these components can differ, but there are 4 basic items you will always need.
The most known component that you will need is a reverse proxy. A reverse proxy is a piece of software, technically a server, which takes incoming external requests and proxies them to your actual service — it’s the way into the cluster. Why is it called a reverse proxy? Because it makes all the services behind the proxy accessible through one single entry point. A normal proxy does the opposite, it establishes an outbound connection for multiple services through one centralized exit point.
Built on a reverse proxy, there is the concept of a load balancer. A load balancer is similar to a reverse proxy but it has an added flavor. While the reverse proxy will just forward a request to one service in the backend (randomly or equally across servers), the load balancer is actually able to manage the distribution of the requests to designated backends. So, it can do weighted load balancing — try to keep things evenly weighted, taxing all servers the same, favoring one server, or enabling functions like version shifting. A load balancer is like a reverse proxy on steroids!
Third, especially in the context of Kubernetes, there is what we call an ingress controller. An ingress controller is also like a reverse proxy, but it looks at your Kubernetes resources (called ‘Ingress’). Ingress controllers work like a routing definition. “Ingress,” in Kubernetes, describes things like a hostname, it might request paths, headers, etc. Based on the information that is provided by the ingress resource, the ingress controller will build the routing for the incoming requests in order to forward them to the actual service. Therefore, an ingress controller is a Kubernetes construct that bridges two worlds, connecting the world of traditional load balancers to that of load balancers in Kubernetes. Last but not least, you also need a valid routable endpoint, for example, a DNS name. We will look more deeply at that in a bit.
Putting it all together
If we look at a typical cloud native architecture, it comes down to this: you have the internet, where a user makes a request — in the diagram below, mydomain.com. Then, you have the routable endpoint — for example, a DNS Hostname — the request will go to the cluster. In the cluster, the request will first meet the reverse proxy, load balancer, or ingress controller, depending on your situation. This piece of technology will then take the incoming request, look at its routing information, and forward it to the correct service depending on how it is configured. For example, Service 1, Service 2, or Server 3 in the diagram.
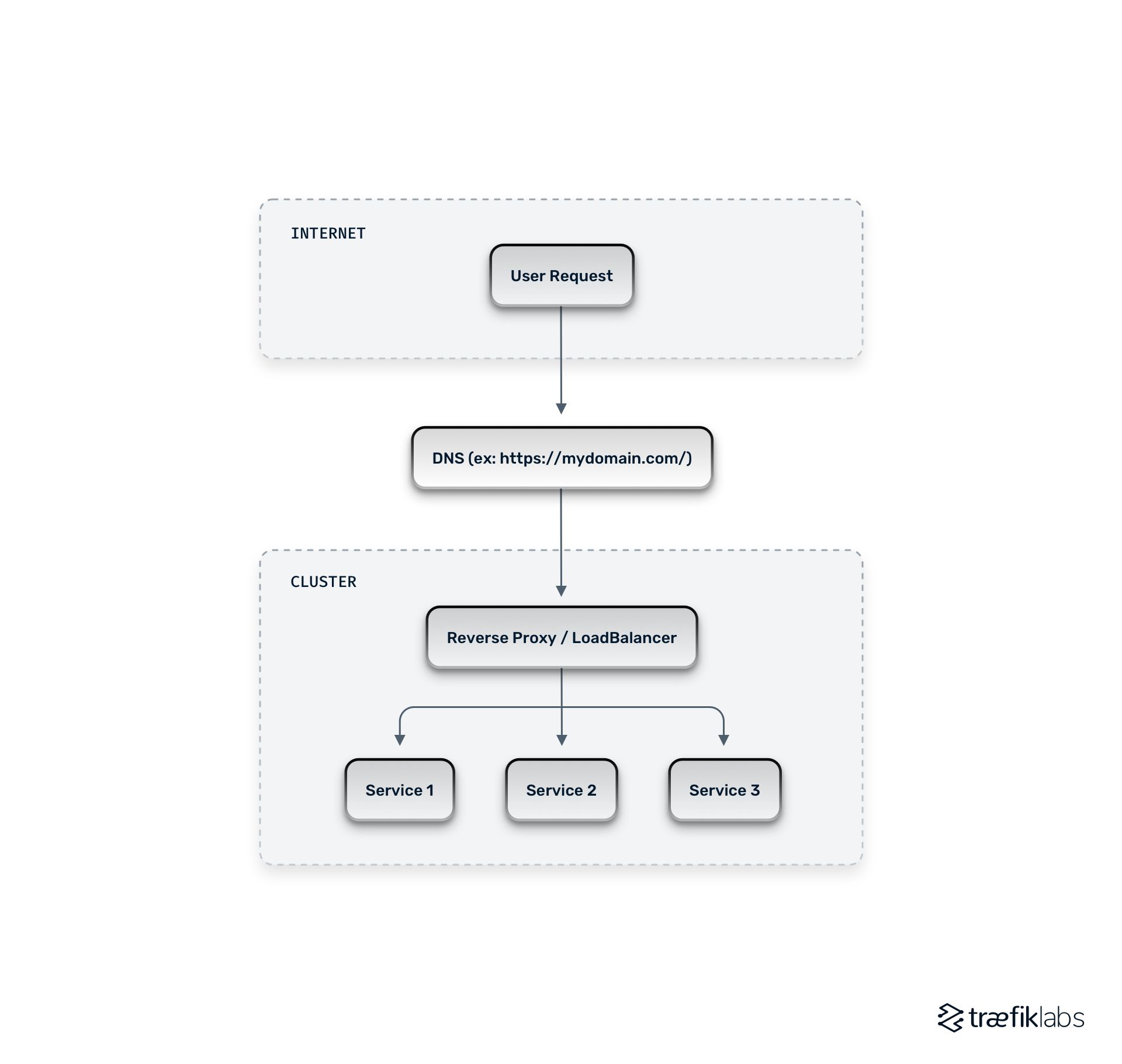
There may be situations where you have an up-front load balancer as well. If you do, then in addition to your cluster — which contains your reverse proxy or load balancer — you may run a load balancer in the cloud (such as Amazon Cloud, Google Cloud, or any other hosting service). If you are using Kubernetes and you want to publish your ingress controller, you will need to have an additional piece of technology called an upfront load balancer.
Why is everything so complicated?! Understanding the OSI networking layers
As you can already see, networking gets very complex, very quickly. But why is that? Well, there is one simple reason for that. Networking consists of several layers, depending on what kind of specification you're looking at. All of those layers have different jobs. If we take the most common structure for these layers, OSI specification, networking is understood as having seven layers. In terms of service publication, the most important layers are Layer 4 (L4) and Layer 7 (L7).

L4 is the transport layer. It is the foundation for everything else because it actually deals with spinning up the connection — spinning up the transport, as the name suggests. Therefore, it works with purely connection-based protocols such as TCP and UDP.
L7 is called the application layer. This layer handles protocols like HTTP, HTTPS, web sockets, gRPC, you name it. Basically, every protocol which you, as a typical developer who wants to publish a microservice, care about. It’s the most commonly used layer by developers for networking. Looking back at the first diagram, the front-end load balancer needs to understand each of these seven levels and take the appropriate actions to complete the request. That would be the job of the ingress controller.
Because we have an ingress controller, we typically also need an upfront load balancer. With an upfront load balancer, we add the next piece of complexity, Network Address Translation (NAT). NAT translates IP addresses to allow intra-network routing. What does that actually mean? It means that if a user requests a given IP, something resolved by DNS, for example, then the request first encounters either your upfront load balancer or your ingress controller. The upfront load balancer or ingress controller then needs to translate the IP addresses from the outside world to the IP address of the container in your microservices.
Generally speaking, we decide between two different types of NAT depending on whether the IP address of the ingress controller (or upfront load balancer) is describing the source of the request or the request destination. As you might imagine, Source NAT (SNAT) translates the IP addresses from the source and changes them using the rules you have specified in the front load balancer. With SNAT, a private IP address is translated into a public one. This is why your home network can use one IP address but still route information to various devices within your home, for example.
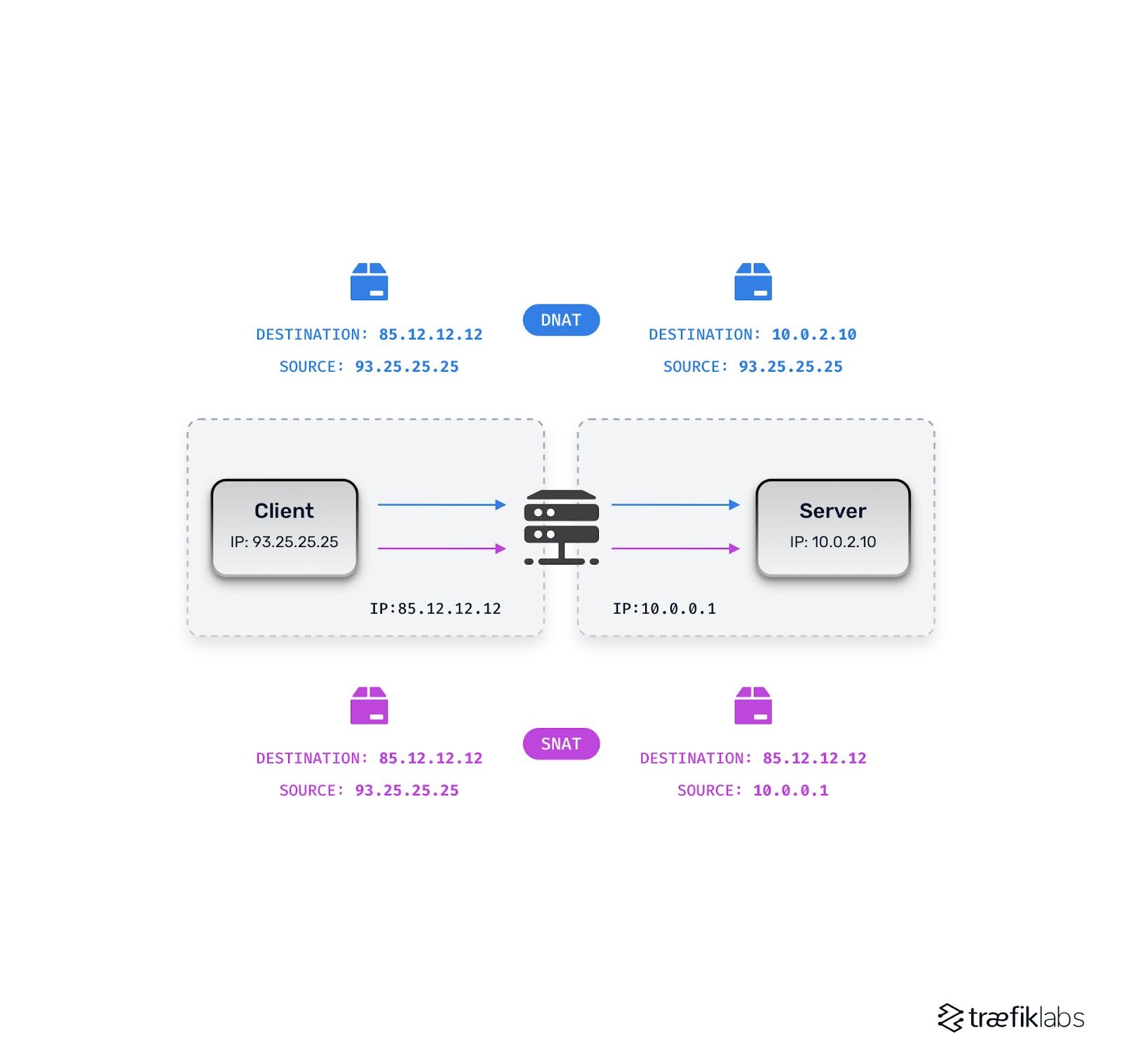
For Destination NAT (DNAT), it's the other way around. Think of DNAT as being about translating the external to the internal. Public IPs are translated into private ones to serve your application. With DNAT, you will always know the original source, but the destination may change. This is important because different upfront load balancers require different techniques. If, for example, you want to ensure that you still know which client (meaning which user) is requesting your service and which real IP address they are using, you need to use the correct type of network address translation.
There are a lot of decisions that you must make to specify how each of your IP addresses will handle the requests process to ensure that those requests result in the desired outcome. The headache only grows as you add each new configuration piece such as firewall rules or port-forwarding]. Automatically resolving NAT for each service you publish would be quite a relief, wouldn’t you say?
Last but not least, we are looking at Domain Name System (DNS). DNS is like a directory for mapping hostnames to IP addresses. DNS is the first component used to reach a cluster because it knows which IP address to contact for a given hostname. If you run any URL — google.com, for example — by DNS, that URL will be resolved to an IP address, and that IP address is what reaches your cluster. In short, DNS is responsible for translating hostnames to IPs and making them available worldwide.
This worldwide availability is a double-edged sword, however. But as it's so widely used around the world, changing DNS settings can be time-consuming. Consider the following scenario. You just deployed your microservice and you want to make it available. You have to instruct your original name server that your new name server, (your new microservice) is available. And this change needs to be propagated worldwide until every DNS server on the planet knows about this microservice. This process can be tedious and takes a long time.
Based on what I’ve explained so far, it is safe to say that networking is painstaking. It requires a multitude of processes and steps to configure things correctly, you must also be incredibly detail oriented to avoid troubleshooting purgatory, and even when you get everything exactly right, you still must wait for DNA to catch up to your changes.
Traefik Hub: the pain relief you’ve been looking for
If the complexity of the most basic example of networking gave you a headache, how would you feel if I told you that there is a simple solution to take care of all your troubles? Traefik Hub was created to solve three major pains in cloud native networking.
- Solve the complexity linked to publishing a service — installing ingress controllers, configuring TLS, and so on and so forth.
- Help organize the networking bits and pieces by hooking up domains, configuring external load balancers for pluggable port forwarding, NAT, and basically organizing all those heavy networking parts we saw earlier.
- Help you protect your services with top-notch access control with and without tunnels to prevent malicious attacks.
Are you hooked yet? It just so happens that we have a new Academy class that will take you from zero to hero on Traefik Hub, for free. After this class, you will be able to publish and secure Kubernetes and Docker containers instantly and at scale whether you use Traefik Proxy or Nginx. Sign up for this hands-on course for free and let’s get rolling!


