


Understanding Multi-Cluster Kubernetes: Architecture, Benefits, and Challenges
Over the years, Kubernetes has helped countless organizations achieve better portability, availability, and scalability for their containerized applications. However, Kubernetes is undeniably complex and consists of many components. And at the heart of this sophisticated machine lies the Kubernetes cluster, a set of nodes that run the containerized applications, making the magic happen.
Although you can run an entire application on a single cluster, that is simply not enough in many cases. By using a multi-cluster Kubernetes architecture, you take advantage of the best this technology offers. But if a single Kubernetes cluster seems complex enough, what happens when you have two, ten, or a hundred clusters?
This article covers the basics of multi-cluster Kubernetes architecture, its benefits and challenges, and why you should consider adopting this deployment method.
What is multi-cluster Kubernetes?
Multi-cluster Kubernetes is a Kubernetes deployment method that consists of two or more clusters. This deployment method is highly flexible. You can have clusters on the same physical host or on different hosts in the same data center. You can also create a multi-cloud environment with clusters living in different clouds and even in different countries.
Multi-cluster Kubernetes architecture
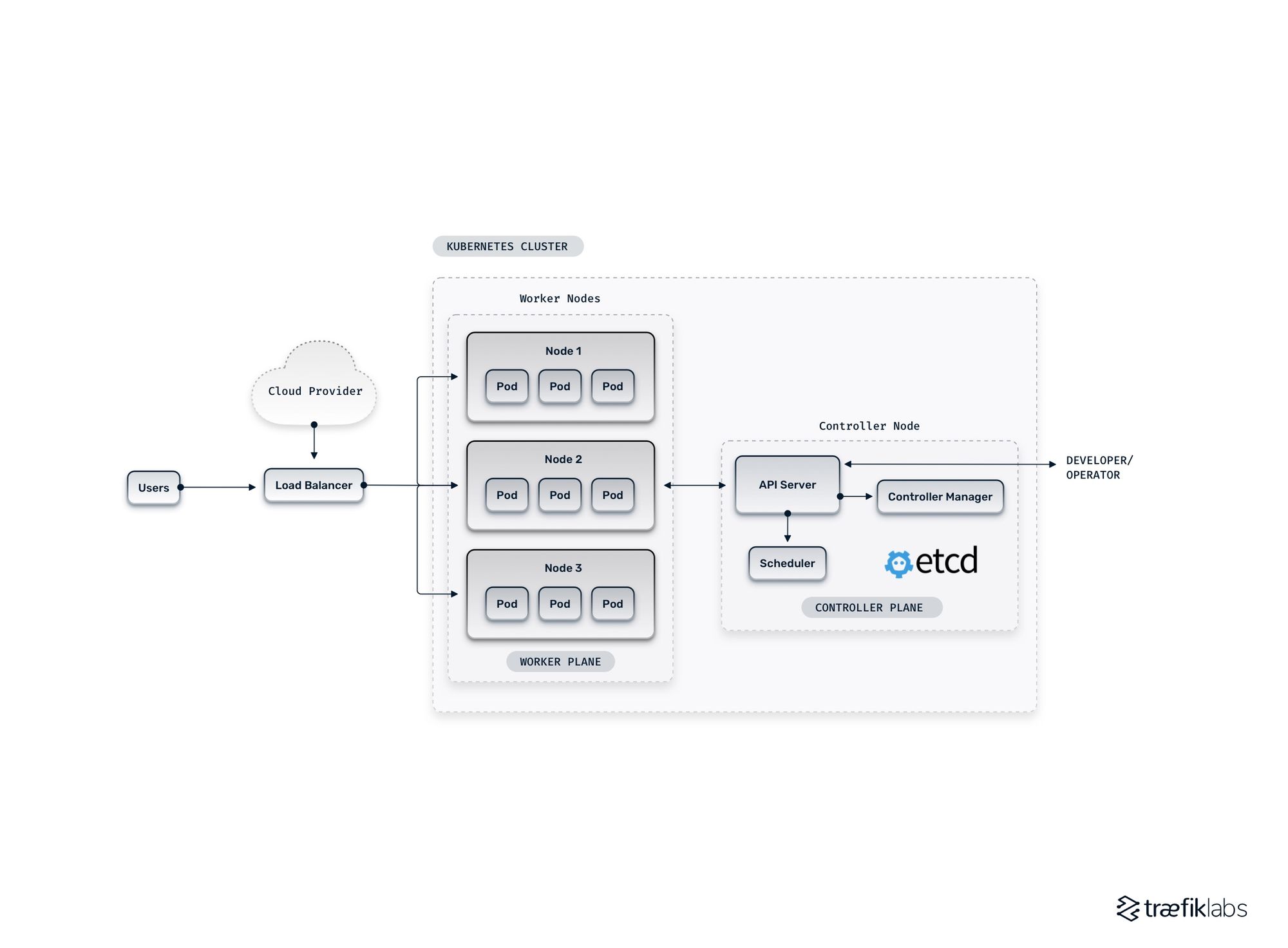
To properly understand the multi-cluster architecture, let’s first have a quick tour of the Kubernetes cluster. A cluster consists of three main planes:
- Control plane: The control brain is considered the brain of the Kubernetes cluster that consists of a few core components, including the API server, the Control Manager, and the Scheduler.
- Data plane: The data plane is the storage of a cluster and is usually implemented through a highly available etcd database.
- Worker plane: You can consider the worker plane as the muscle that runs the actual workloads in a cluster and consists of nodes that contain pods.
The diagram below shows a simplified representation of a single Kubernetes cluster.
A multi-cluster architecture builds on this single-cluster as shown in the diagram below:
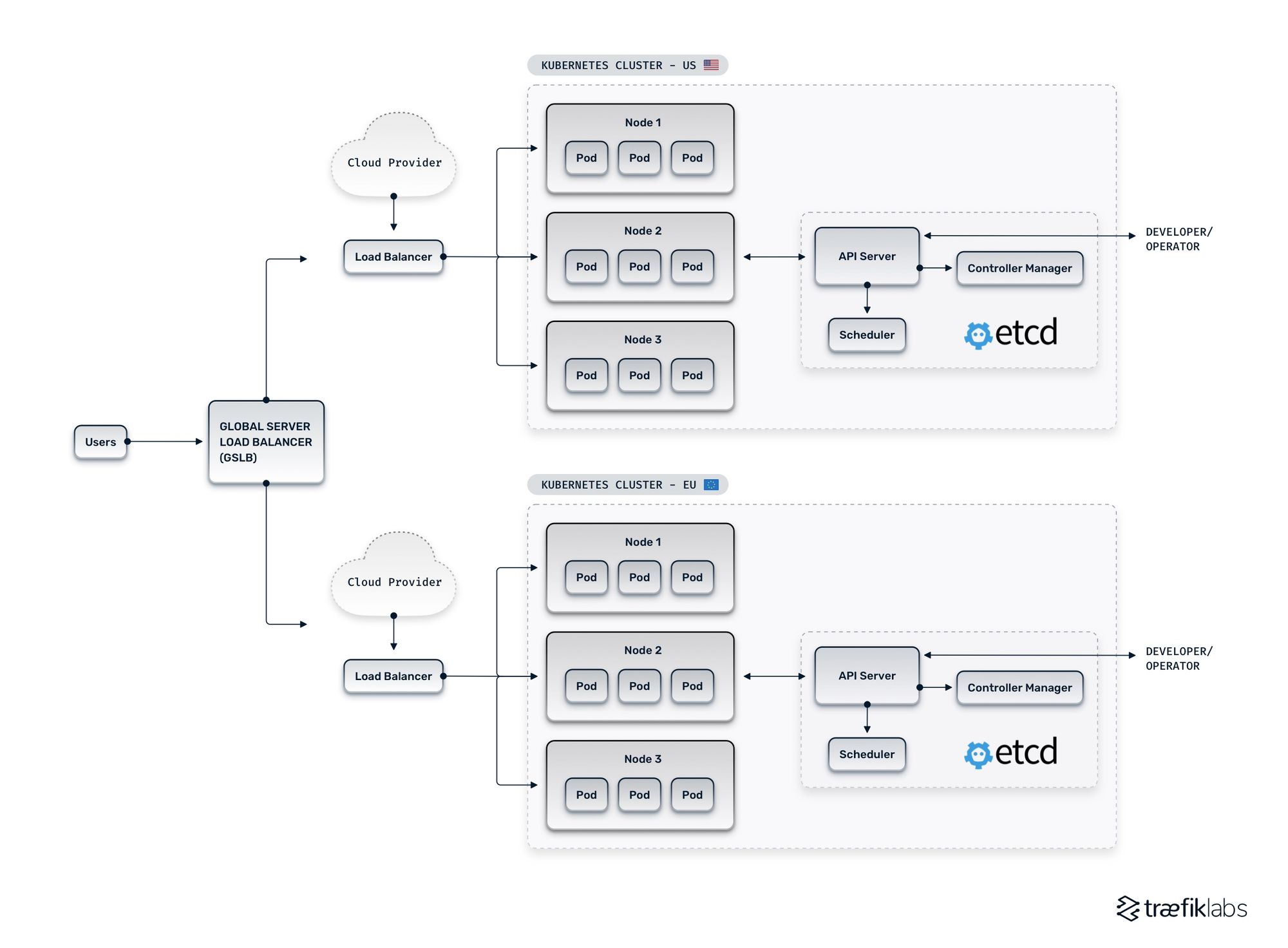
So, where is the complexity with that? A multi-cluster architecture does not look all that complex and scary in its simplest form. But in reality, there are various ways to design a multi-cluster
Kubernetes architecture. The example above depicts the cluster redundancy architecture. In this case, the two Kubernetes clusters are exact replicas of each other.
The architectural design choice is based on the two main architectural approaches — segmentation vs. replication.
Multi-cluster architecture designs: segmentation vs. replication
With the segmentation approach, the application is divided into independent components, commonly represented as Kubernetes services, that get allocated to different Kubernetes clusters according to operational requirements.
On the other hand, with the replication approach, exact copies of a Kubernetes cluster are hosted in many data centers across different locations. This provides redundancy, ensuring your application remains accessible in the scenario of one cluster becoming unavailable.
Kubernetes-centric vs. network-centric configuration
Another important piece of the puzzle is the configuration of Kubernetes clusters. There are two primary methods of handling multi-cluster Kubernetes environments — Kubernetes-centric vs. network-centric. When using the Kubernetes-centric method to handle a multi-cluster environment, you have different applications running on different Kubernetes clusters. Still, you are managing all of them from a central location.
With the network-centric method, an exact replica of the application is deployed in multiple clusters in different locations. Although these clusters behave as separate entities, you maintain communication between all of your Kubernetes clusters through a network.
The benefits of using a multi-cluster architecture
The core element in all architectural designs is the independence of each cluster, and therein lies the critical advantage of the multi-cluster Kubernetes architecture. But the range of the real-life benefits of multi-cluster Kubernetes goes beyond that.
Flexibility
Multiple clusters give a significant amount of flexibility and control over the choice of design and configuration. For example, you can use different versions or distributions of Kubernetes in different clusters to meet particular needs or requirements for various parts of your applications. With the multi-cluster architecture, you can also test different or newer versions of Kubernetes in isolated clusters before upgrading your production environment, minimizing the risk of breaking changes and downtime.
Availability, scalability, and resource utilization
One of the greatest advantages of multi-cluster deployments is improving Kubernetes performance, especially in terms of availability and scalability. With a multi-cluster architecture, you can move workloads between clusters. You can use one cluster as backup and spread clusters across different data centers, locations, and clouds. And by doing so, you minimize the risk of your entire environment going down because of a single cluster failure.
By deploying clusters in different locations, you decrease the physical distance between the cluster hosting your application and the end-user, increasing performance and minimizing latency.
Having workloads distributed across different clusters also leads to higher scalability. Multi-cluster Kubernetes allows you to scale up and down different clusters according to their specific load — this optimizes resource utilization by adjusting resources to meet different performance requirements.
Workload isolation
As mentioned earlier, the independence of clusters that allows for complete workload isolation is the key benefit of this architecture. Granted, a certain level of isolation can be achieved even in a single-cluster architecture using namespaces. However, in the single-cluster scenario, environments are not perfectly isolated from each other due to the peculiarities of the Kubernetes security system. When using this method of isolation within the cluster, applications that share the same hardware can affect each other — also known as the “noisy neighbor” issue.
By running workloads across multiple Kubernetes clusters, you benefit from a high isolation level. Potential cluster failures or configuration changes affect only that specific cluster. Workload isolation is key to development teams as it helps them easily isolate and diagnose issues, test new features and configurations, improve and upgrade applications, and all that while keeping the production environment safe and available.
Security and compliance
With the high workload isolation provided by the multi-cluster architecture, you minimize the risk of unrelated applications interacting with each other in unintended ways. Strict isolation also reduces the risk of a security issue in one cluster affecting your entire environment. This can also be achieved to some extent within a single Kubernetes cluster using pod security policies, for example. But nothing can compare to the high workload isolation that comes with multi-cluster Kubernetes.
Multi-cluster deployments also make it easier to comply with different regulations and policies across different countries. A great example of this is the General Data Protection Regulation (GDPR) in the EU. GDPR mandates that user data do leave the EU. If you have users worldwide and run your application in a single cluster, it would be nearly impossible to comply with these requirements. With multi-cluster deployments, you can deploy a cluster in the EU to address these needs and comply with local regulations while running other clusters elsewhere.
The challenges of multi-cluster Kubernetes
Very few good things in life come with no obstacles to overcome, and Kubernetes is definitely not one of them. Despite the endless possibilities and the important advantages that come with multi-cluster Kubernetes deployments, there are a few challenges involved.
Complexity
This has been mentioned a few times already — Kubernetes has a high level of complexity, and multi-cluster Kubernetes is even more so. The added complexity can take a number of forms. Here are a few of them:
Configuration
Depending on your architectural design, different clusters in your environment require different configurations to meet the specific needs of each cluster. That is detailed work, and there is no way around it. Another level of the same challenge is the firewall configuration. In a single-cluster architecture, you are accessing a single API server at a specific address.
With a multi-cluster deployment, you're accessing a number of API servers, and you need to make sure that the firewall allows access to API servers in related clusters. To mitigate this, you can make use of automation scripts that, unfortunately, also add to the level of complexity.
Security
Security is considered a major benefit of multi-cluster deployments — why is it considered a challenge as well? Indeed, the workload isolation in multi-cluster Kubernetes aids a better security posture, but in order to achieve that, you need to take into account the different set of rules and security certificates you need to follow for each cluster — remember the example of the EU-specific regulations (GDPR). To be compliant with different local regulations, you need to manage these security certificates across different datacenters and clusters.
Deployment
Naturally, deployments in a multi-cluster Kubernetes architecture become increasingly complex. This is particularly true when using the GitOps approach. In GitOps, your source code management (SCM) service is the single source for all your deployment activity. This means that your GitOps processes must be well-organized, secure, and smart. Despite the obvious hassle that comes with this approach, GitOps can help you automate the configuration of clusters, empower you to own the lifecycle of Kubernetes clusters, and deploy at scale.
Cost
Another challenge to consider when adopting a multi-cluster Kubernetes architecture is a potentially significant increase in costs. More clusters mean more nodes, which in turn results in an increase in resource usage and, ultimately, costs. Another important aspect to keep in mind is the need for an increased number of load balancers, ingresses, as well as logging and monitoring resources.
Summary
A single Kubernetes cluster offers a good number of options and possibilities. However, if you are looking for better flexibility, scalability, resilience, and security, then multi-cluster architecture is the better option for your application.
That does not mean that multi-cluster Kubernetes can be considered a walk in the park — despite the important advantages that come with it, there are some serious challenges you need to consider. In any case, the key to making a decision between a single-cluster or a multi-cluster architecture is that the benefits outweigh the challenges and costs involved.
But if you do decide to adopt the multi-cluster architecture, there is a plethora of tools and strategies that can help you ease the complexity that comes with application networking at scale. Check out one of our latest webinars From Chaos to Controlled: How to Simplify Multi-Cluster Networking for All Your Applications, and learn how Traefik Enterprise can help you to
- make your existing cloud architecture more efficient
- automate service discovery and configuration
- control routing across clusters and orchestrator types
- and more!